Рис. 1. Сайт Мировой цифровой библиотеки
Централизация или распределение: два подхода к созданию цифровых библиотек на примере The European Library и World Digital Library
Шварцман М.Е.
(Российская государственная библиотека)
Желание объединять свои цифровые ресурсы в различные межбиблиотечные коллекции и делать их доступными в составе этих коллекций, то есть стремление к интеграции, возникло сразу после подключения библиотек к сети Интернет. Поэтому сейчас, в связи с накоплением большого количества цифровых ресурсов и увеличением скорости передачи данных в Интернет, мы наблюдаем рост количества интегрирующих проектов, объединяющих различные библиотечные, музейные, архивные и прочие электронные ресурсы и делающие их доступными в Интернет.
Методы интеграции бывают различными. Вначале, как мы помним, появились первые каталоги полнотекстовых ресурсов Интернет, собираемые энтузиастами. Один из таких «Регистр полнотекстовых и справочных ресурсов Интернет» до сих пор поддерживается РГБ http://dc.rsl.ru/dc_bib.htm. Далее стал применяться протокол Z39.50, особенно в проектах корпоративной каталогизации. Стали создаваться шлюзы Z39.50, например, в БЕН РАН http://www.benran.ru/Zgw/. С этого момента и началась собственно интеграция различных библиотечных систем и электронных библиотек. Методы интеграции можно классифицировать по степени централизации данных и метаданных. При работе шлюза Z39.50 и данные, и метаданные остаются у своих владельцев и только в результате распределенного поиска метаданные из различных источников собираются в одной форме выдачи результатов. Следующая степень централизации – это предварительный сбор метаданных на одном сервере и проведение поиска уже в единой базе. И, наконец, максимальная степень централизации – это сбор и данных, и метаданных в одном месте. Про Z39.50 и теоретические аспекты остальных методов написано уже много, поэтому предметом обсуждения в данной статье является практическая реализация двух различных методов интеграции цифровых библиотек – использованного Евросоюзом для создания Европейской библиотеки и Библиотекой Конгресса США для организации Мировой цифровой библиотеки.
Как же устроена Мировая цифровая библиотека (World Digital Library – WDL)?
Известно, что Библиотека Конгресса США получила грант от Google в размере $ 3 000 000 на создание пилотного проекта WDL. Основными принципами, принятыми при создании WDL, были:
Для реализации этого проекта в Библиотеке Конгресса было создано специальное подразделение из нескольких человек, которое собирало у участников проекта (а их было чуть более 30 и из них трое российских) цифровые объекты и их описания. Причем были разработаны довольно высокие требования к качеству изображения, принимались только файлы в формате tiff и с разрешением не менее 300 dpi. Все описания редактировались и переводились за счет гранта. Параллельно разрабатывалось программное обеспечение, позволяющее опубликовать собранную коллекцию. Поскольку трудозатраты на подготовку данных оказались велики, в итоге в WDL было загружено всего около 1000 объектов. После этого средства гранта закончились, и теперь руководство проекта ищет средства на продолжение этой работы. Бизнес-модель проекта изначально подразумевала, что все объекты и их описания собираются в одном месте, всей обработкой занимается штат проекта, и от партнеров только требуется передавать материалы. Заинтересованность их в проекте обусловливалась либо денежным вознаграждением, либо, как в случае с РГБ, предоставлением соответствующего количества отсканированных материалов из фонда Библиотеки Конгресса США, необходимых для обслуживания читателей РГБ.
Рис. 1. Сайт Мировой цифровой библиотеки
В итоге, получившаяся WDL http://www.wdl.org/ru/ представляет собой очень красивую и очень удобную, но очень маленькую коллекцию, развитие которой невозможно без большого финансирования. Такая бизнес-модель изначально была, на мой взгляд, обречена на неуспех, потому что нельзя рассчитывать на постоянные гранты при планировании такой большой работы.
Противоположный подход был принят при создании The European Library (TEL) http://search.theeuropeanlibrary.org/portal/ru/index.html . Как же она устроена? TEL- это консорциум национальных библиотек Европы, в котором участвуют практически все страны (48 национальных библиотек). Эта система предполагает централизованное хранение метаданных и децентрализованное хранение цифровых объектов. Строго говоря, система рассчитана не только на сбор информации о цифровых объектах. В центральном индексе системы собирается информация обо всех библиографических записях, хранящихся в электронных каталогах национальных библиотек. Если в записи есть ссылка (URL) на цифровой объект, то она также передается. Сбор информации происходит по протоколу OAI- MH. Робот, с заданным интервалом времени, обходит все электронные каталоги библиотек-участниц проекта, поддерживающие протокол OAI и собирает новые библиографические описания. Описания хранятся в формате Dublin Сore на центральном сервере системы. К сожалению, далеко не все библиотечные каталоги в настоящее время поддерживают протокол OAI- MH. Некоторые поддерживают только Z39.50, некоторые только SRU. Поэтому при поиске информации используется гибридная технология объединения результатов, полученных из разных источников. Как показано на рис. 2, поисковый запрос посылается одновременно в несколько мест:
Шлюз Z39.50
Шлюз SRU
Центральный индекс
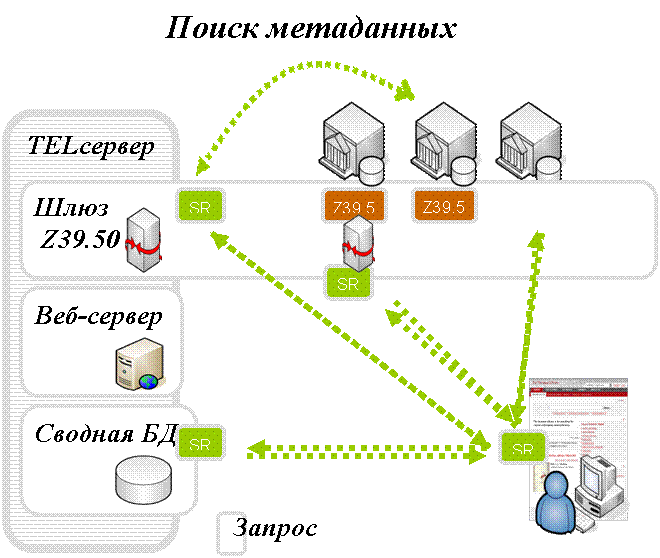
Рис 2. Схема прохождения запроса в TEL
В итоге мы получаем обобщенный результат, как показано на рис.3.
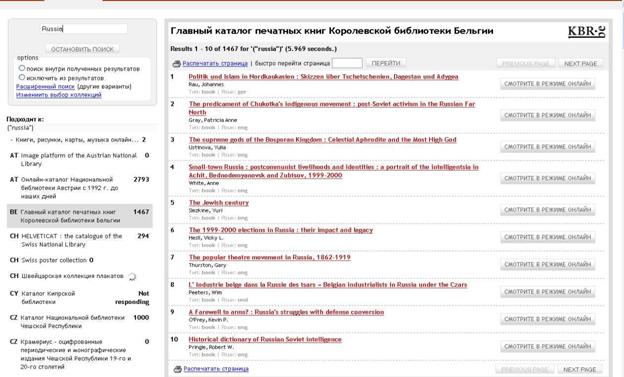
Рис. 3 обобщенный результат по запросу «Russia».
Чем большее количество участников проекта будет использовать протокол OAI- MH, тем более полным будет центральный индекс. Соответственно, тем больше сервисов сможет предложить TEL своим участникам. Например, результаты, полученные по Z39.50 от разных источников, очень сложно ранжировать, кластеризовать и проводить с ними дополнительные работы. Но при получении ответов от одного источника таких проблем не возникает. При накоплении большого количества метаданных, полученных от разных участников, можно попробовать автоматически составлять описания в соответствии с «Функциональными требованиями к библиографическим записям» (FRBR). Такие работы уже ведутся и дают весьма интересные результаты. Действительно, объединяются описания одинаковых произведений одного автора, изданные в разных странах и на разных языках.
Для того, чтобы все библиотеки могли отдавать свои библиографические описания в общее хранилище, в рамках проекта было разработано программное обеспечение REPOX, позволяющее загружать в свою внутреннюю базу записи в формате MARC21, UNIMARC или Dublin Core и способное отдавать эти записи по протоколу OAI- MH. Поскольку у всех библиотек-участниц имеется свое понимание того, что считать правильным MARC21, в REPOX предусмотрен механизм визуальной настройки таблиц соответствия при конвертировании (см. рис 4)
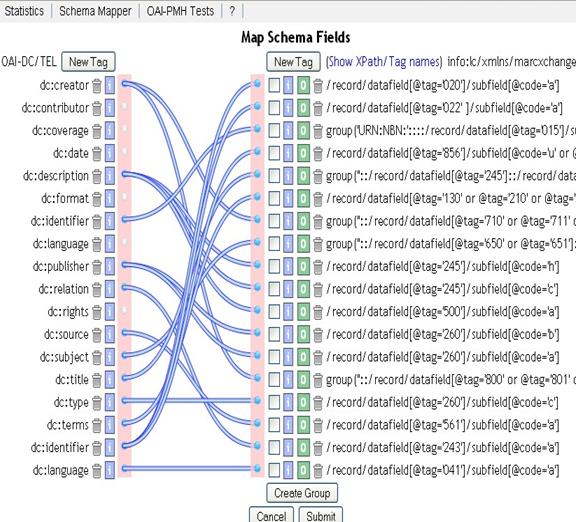
Рис. 4. Механизм визуальной настройки таблиц соответствия
Таким образом, каждая библиотека может выгрузить из своего каталога те библиографические записи, которые она хочет, чтобы взял сборщик OAI записей. При этом таким сборщиком-интегратором могут быть не обязательно только сервера проекта TEL. Можно собирать записи, объединяя институтские коллекции по заданной теме. При этом одни и те же выгруженные записи могут собираться различными сборщиками для различных проектов.
Так, например, в РГБ планируется совместный с Казахстаном проект «Встреча на границах», в рамках которого объединяются библиографические записи об изданиях, хранящихся в приграничных библиотеках на тему о Российско-Казахстанских отношениях. Поскольку в казахских АБИС протокол OAI не поддерживается, то REPOX будет единственным средством для предоставления ими своих записей. Параллельно начинается работа по проекту «Достоевский - Валиханов» о дружбе и взаимодействии двух великих людей. В этом проекте, вполне возможно, будет принимать участие кто-то из вышеописанного проекта, и библиографические записи, доступные по OAI в REPOX по первому проекту, будут собраны и для второго проекта. Для сбора записей в таких проектах можно порекомендовать Open Archives Harvester http://pkp.sfu.ca/?q=harvester , разработанный в Университете Симона Фрезера в Канаде.
Возвращаясь к выбору модели интеграции, хочется отметить как развитие TEL проект Европеана http://www.europeana.eu/portal/index.html, в котором тоже принята технология сбора метаданных по OAI и отсылка к цифровым объектам, хранящимся у участников проекта. Сейчас там уже собрано более 4 000 000 записей, и к 2010 их число достигнет 10 000 000.
При этом основные затраты на оцифровку, описание, публикацию несут сами участники. Интеграционная составляющая – это расходы на сбор и публикацию метаданных, согласование форматов.
Если мы сравним результаты WDL и TEL, то можно сделать следующий вывод.
Библиотеки готовы объединяться, если им при этом не нужно отдавать свои цифровые объекты и проводить какие-то специальные трудоемкие работы для такого объединения.
К сожалению, в России сейчас всего несколько электронных каталогов поддерживают OAI, будем надеяться, что ситуация изменится, и основные интеграционные процессы будут проводиться именно на основе OAI.
Литература