ИНТЕГРАЦИЯ НАУЧНОЙ ИНФОРМАЦИИ В ЕНИП
Сысоев Т.М., Дьяконов И.А.
(МСЦ РАН) (ВЦ РАН)
Единое научное информационное пространство
Единое научное информационное пространство представляет собой проект, направленный на объединение научной информации, опубликованной институтами и подразделениями РАН. Цель проекта — предоставить пользователям возможность доступа к объединённому, цельному представлению данных, расположенных в различных информационных системах организаций РАН, как правило, доступных в сети Интернет. Следует подчеркнуть, что объединение предполагается виртуальное, то есть не предполагает создания некоторого единого хранилища для данных — при весьма больших объемах информации такой подход был бы неэффективен как в плане требуемых вычислительных ресурсов, так и с точки зрения поддержки информации в актуальном состоянии. Вместо этого, в рамках инициативы ЕНИП предлагается набор стандартов для описания информационных ресурсов и набор протоколов, с помощью которых осуществляется взаимодействие между участниками ЕНИП. Это позволяет создать “надстройку” над уже сложившейся инфраструктурой, которая позволит, прежде всего, выполнять поиск научной информации унифицированным образом.
В настоящее время практически каждая организация РАН представлена в сети Интернет собственным веб-сайтом, на которых, в большинстве случаев, опубликована контактная информация, данные о сотрудниках и результатах их научной деятельности, структура и состав подразделений. Принятый в Интернет способ представления данной информации с помощью языка разметки HTML не позволяет поисковым машинам “понимать”, о чём идёт речь, для них доступен только текст. В результате качество поиска и его возможности оставляют желать лучшего. Например, мы не можем ограничить поиск только публикациями, или получить список персон, получивших учёную степень по какой-либо специальности в указанный период времени. Данная проблема характерна для всей сети Интернет в целом, и для её решения была создана инициатива “Semantic Web” [1], которая, в частности, предлагает стандарты для описания информационных ресурсов, пригодные для автоматической компьютерной обработки. Вместе с обычной текстовой информацией, предназначенной для посетителей веб-сайтов, его редакторы могут опубликовать описание в специальном формате, в результате чего поисковые системы получат информацию о структуре и связях представленных на сайте ресурсов.
На ЕНИП можно смотреть как на реализацию этого подхода в масштабах РАН. Поскольку Semantic Web описывает лишь технологии, остаётся свобода выбора в том, как их применять. Поэтому для ЕНИП предлагается набор стандартов описания научных информационных ресурсов и ряд протоколов, с помощью которых происходит взаимодействие между серверами.
Для описания ресурсов применяется модель данных RDF, предложенная в Semantic Web. Ресурсы описываются в соответствии с разработанными схемами данных, которые определяют такие понятия, как классы ресурсов, их свойства и связи. Там, где возможно, предлагаемые схемы данных используют популярные международные форматы, в частности, Dublin Core [2], Prism [3], vCard [4]. Не требуется, чтобы информационный ресурс был описан полностью, но, в то же время, описание должно быть достаточно удобным для пользователей системы, то есть в нём должны присутствовать свойства, по которым пользователь сможет эту информацию найти. Например, пользователь может выполнить поиск интересующей его персоны по фамилии и научной степени, перейти на сайт ресурса, на котором эта персона представлена, и получить о ней достаточно подробную информацию, в том числе, не представленную в исходном описании.
Протоколы взаимодействия являются достаточно простыми в использовании и следуют архитектуре веб-сервисов, наиболее хорошо зарекомендовавшей себя для работы в Интернет. Они основаны на идеях, предложенных в таких стандартах, как CIP и SDLIP, и представляют собой упрощение и адаптацию этих протоколов к стандартам WSA.
Структура ЕНИП/P>
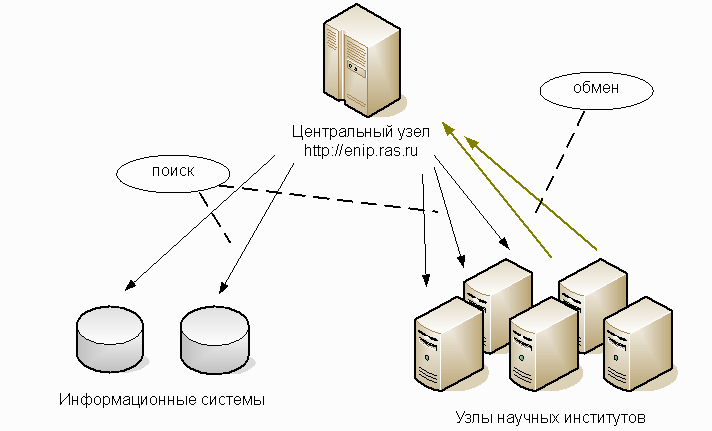
Рис. 1. Типы узлов ЕНИП
На рисунке 1 представлены типы узлов ЕНИП и способы их взаимодействия на текущий момент. Можно выделить следующих участников:
В настоящее время большинство узлов ЕНИП построено на информационной системе “Научный институт РАН” [6] — типовом решении, позволяющем публиковать научную информацию какой-либо организации, в последнюю версию которого встроена поддержка протоколов взаимодействия ЕНИП. В частности, на этом решении работают серверы Пермского научного центра, Института механики сплошных сред, Санкт-Петербургского научного центра. В то же время подключены и информационные системы, построенные на других технологиях, например, данные Библиотеки по естественным наукам РАН и Научно-образовательная социальная сеть “Соционет”.
По мере развития системы будут добавляться новые серверы верхнего уровня, которые обеспечивают маршрутизацию запросов, например, по географическому принципу. Также в ближайшее время планируется подключение службы хостинга, которая позволит публиковать данные организациям, не имеющим своей информационной системы.
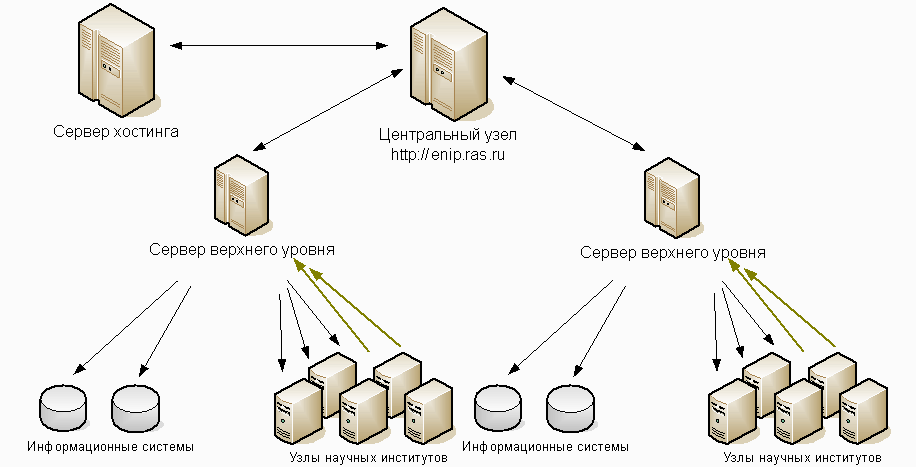
Рис. 2. Развитие ЕНИП
Интеграция существующих информационных систем
Архитектура ЕНИП позволяет подключать существующие информационные системы с помощью программных компонент — адаптеров. Допустимы различные способы интеграции, которые различаются по сложности их реализации.
Самым простым способом интеграции является интеграция с помощью экспорта данных в информационную систему, которая может участвовать в процессах распределённого поиска и обмена. Такой системой может быть как существующий узел ЕНИП, так и, например, новый узел, работающий на программном обеспечении “Научный институт РАН”. На практике это означает, что к существующей информационной системе создается “надстройка”, в задачи которой входит преобразование данных к стандартному формату, используемому в ЕНИП. Для реализации такого способа интеграции, необходимо выполнить следующие шаги:
Первый шаг — отображение схемы данных на OWL/RDF-модель необходимо выполнять с учётом того, что к настоящему моменту разработаны рекомендуемые схемы для метаинформации [5], в том числе так называемая “базовая” схема, которая поддерживается всеми участниками ЕНИП. Таким образом, отображение должно производиться так, чтобы конечный результат соответствовал базовой схеме. Базовая схема позволяет описывать информацию о сотрудниках организации, результатах их научной деятельности, структуре подразделений. Соответственно, при интеграции с помощью экспорта информация для участников ЕНИП будет доступна в объёме, соответствующем базовой схеме. При необходимости сделать доступными более специализированные, тематические данные, данный метод интеграции не подходит, и вместо него следует реализовать поддержку протокола распределённого поиска.
На этом шаге также следует выбрать схему именования информационных ресурсов. В ЕНИП каждому информационному ресурсу сопоставляется уникальное в рамках распределённой среды имя. Уникальность имени обеспечивается соглашениями по его структуре: первая часть содержит идентификатор узла ЕНИП, вторая — идентификатор информационного ресурса в рамках данного узла. В качестве идентификатора узла ЕНИП допустимо использовать DNS имя, по которому доступна информационная система. Идентификатор ресурса в рамках узла получается достаточно просто, например, в случае реляционной СУБД можно использовать строчку, состоящую из имени сущности и первичного ключа.
Далее следует определить, какие свойства из базовой схемы метаданных присутствуют в информационной системе. Свойства типа строк, дат и чисел форматируются в соответствии со стандартом XML Schema– Data Types. Отдельного внимания потребуют свойства, значения которых являются элементами словарей или рубрикаторов. В этом случае необходимо будет построить соответствие между применяемой в информационной системе классификацией (например, научных степеней), и предложенными в схемах метаданных словарями.
После выполнения данных шагов реализация программных компонентов, обеспечивающих экспорт данных, как правило, сложности не представляет. Для реляционной СУБД достаточно получить необходимую информацию с помощью SQL запроса, и оформить конечный результат в RDF/XML виде. Если для системы предусмотрен XML-формат экспорта (например, RSS), то может быть более просто, по сравнению с непосредственной работой с базой данных, составить для XML данных XSLT-преобразование, которое переведёт данные в нужный формат. Например, такой подход применяется при загрузке в ЕНИП данных из Научно-образовательной социальной сети “Соционет”.
В реализуемом компоненте необходимо предусмотреть возможность инкрементальной выгрузки, т.е. режим, в котором выгружаются только новые и изменённые с момента предыдущей загрузки данные. Реализация зависит от конкретной информационной системы. Обычно для этого потребуется таблица, в которой будут сохраняться идентификаторы выгруженных ресурсов и время их модификации.
Для экспорта данных в узел ЕНИП потребуется следующая информация:
Эту информацию можно получить у администратора соответствующего узла. Для узлов, построенных на информационной системе “Научный институт РАН”, адрес сервиса обмена имеет стандартный URL вида http://(имя узла)/services/Exchange. Загрузка данных осуществляется с помощью SOAP вызова. Сообщение SOAP представляет собой стандартную “обертку” над экспортированными RDF/XML данными, поэтому формируется достаточно просто. Ответ от сервиса обмена представляет собой сообщение со списком идентификаторов загруженных ресурсов, а также со списком обнаруженных во входных данных ошибок.
При наличии достаточных вычислительных ресурсов можно поднять собственный экземпляр информационной системы “Научный институт РАН”, предназначенный для выгрузки данных — в таком режиме она используется как дополнительное RDF-хранилище, обеспечивающее в необходимой степени поддержку протокола поиска.
Интеграция с помощью поддержки протокола поиска требует несколько больших усилий, но в конечном итоге является более эффективной, поскольку отсутствует дополнительная прослойка между информационной системой и ЕНИП, и пользователям предоставляется актуальная на данный момент информация. При таком способе интеграции ссылки о результатах поиска ЕНИП будут вести непосредственно на страницы интегрируемой информационной системы. Кроме того, поиск может выполняться по дополнительным атрибутам, отсутствующим в базовой схеме.
В общем случае для поддержки интеграции с помощью протокола поиска требуется выполнить следующее:
Реализация протокола поиска может быть непростой задачей, поскольку, помимо атрибутного поиска, в выражениях допускается также полнотекстовый поиск. Как следствие, ресурсы должны быть доступны по полнотекстовому поиску всех их атрибутов. Это не всегда выполнимо, поскольку в реальных информационных системах часть атрибутов может быть не предназначена для поиска, не везде реализован полнотекстовый поиск, а если и реализован, то индекс может строиться не по всем атрибутам или без выделения атрибутов. Тем не менее, сам протокол является достаточно простым, и если необходимый для операции поиска функционал поддерживается, то его реализация сложности не представляет.
Благодаря открытости архитектуры и протоколов, можно решить и обратную задачу: использование сервисов ЕНИП в существующих информационных системах. Основным вариантом использования в таких случаях является функция поиска. Описанным выше протоколом поиска можно воспользоваться для того, чтобы искать данные, в том числе одновременно в ряде узлов.
Заключение
Единое научное информационное пространство представляет собой важную и актуальную инициативу, направленную на повышение открытости и доступности научной информации РАН, что, в конечном счете, приведет к более тесному сотрудничеству между научными коллективами, повысит эффективность их работы. В то же время, развитие этого проекта невозможно без активного участия и поддержки научными организациями, которая не в последнюю очередь зависит от удобства и простоты процесса интеграции, высокоуровневое описание которого приведено в данной статье.
Литература