
SOS — SOS — SOS
Жучков А.В., Кравченко А.В., Твердохлебов Н.В.
(Институт
химической физики им. Н.Н Семенова РАН,
Москва)
Введение
Ответ на вопрос о коэффициенте полезного действия современных информационных технологий, конечно, может быть разным в зависимости от того, кто и в какой ситуации отвечает на него, однако очевидно, что все, а особенно потребители информации, согласятся с тем, что он несоразмерно низок относительно затрат на эти информационные технологии. Причину многие видят в компаниях — поставщиках решений — Application Service Provaiders (ASP). Простое объяснение — компании предлагают неудачные решения или недостаточно компетентны. Однако, скорее всего причина глубже, ведь в подавляющем большинстве ASP — не что иное, как операторы чужих решений, опирающиеся только на свои связи с поставщиками и клиентами.
Как получить услугу напрямую у разработчика с поддержкой, легально и дёшево? Оказывается, что такая возможность существует. И это — не покупка и эксплуатация программ (прикладных или системных), а использование среды сервисов. При этом не надо думать о других программах, установленных или нет на твоем компьютере, о том, заработает ли купленное программное обеспечение, хватит ли ресурса у твоей машины, как быстро придётся обновлять версию и т.д., а надо просто заказать решение своей задачи при помощи доступного экземпляра нужного сервиса.
Следует сказать, что учёные уже активно пользуются такими средами, например OSG (http://www.opensciencegrid.org/), EGEE (http://www.eu-egee.org/) или Виртуальные обсерватории (http://www.virtualobservatory.org/). Практически все эти среды создаются с применением Грид-технологий. Критическая масса таких инструментальных средств фактически создаёт новую технологическую версию обеспечения науки — Science2.0/
Сервис-ориентированный подход и Science2.0
Известно, что Грид-концепция родилась в среде научного сообщества, которое испытывало острую потребность в развитых средствах поддержки сотрудничества. Современные методы научно-исследовательской работы таковы, что ни один крупный научный проект не осуществляется силами одного, административно-замкнутого коллектива исследователей. Исследования ведутся в колаборациях ученых как географически, так и административно распределенных. Виртуальные организации (ВО) [1], как объединение ИТ-инфраструктуры и ученых явились крайне удачной абстракцией, поддерживающей различные формы взаимодействия.
При этом компьютерно-ориентированные исследования, исследования in silico, как ни какая иная сфера деятельности оперирует огромнейшими массивами этих данных. В процессе работы над научными проектами продуцируются огромные массивы данных, разнородных по своей природе, которые накапливаются как в закрытых, так и в открытых, доступных через Интернет источниках. Когда данных становится очень много, они как бы сами начинают порождать новые данные. Многие стали говорить — теперь это не Silico Oriented Science (SOS), а Silo Oriented Science (SOS) [2]. Эта игра слов подчёркивает ситуацию, в которой научные данные многих проектов, по сути, представляют собой эти самые слабо структурированные и слабо связанные данные — “силосные хранилища”, работа с которыми очень сложна.
Действительно, в ВО учёные, как правило, взаимодействуют именно со слабо структурированными и слабо связанными данными. Следуя современной терминологии, будем называть их пространствами данных (ПД) [3].
Есть ещё одно важное наблюдение: ученые вообще не очень любят работать с БД. В информационном хаосе легче найти новые знания, нащупать новые подходы, есть больше возможностей применить свою интуицию и нестандартные варианты решений. То есть, очевидно, что в этой среде придётся мириться с существованием ПД, а тогда практически единственным выходом из такой ситуации является наполнение такой среды информационными сервисами. Этот сервис-ориентированный подход и должен привести к построению Service Oriented Science (SOS).
Сервисный подход — это, по сути, эволюция ПО. Он провозглашен достаточно давно, но становится востребованным именно теперь и во многом из-за необходимости обслуживания ВО. Основным достижением Грид-технологов, бесспорно можно считать разработку стандарта архитектуры программного обеспечения Грид — Open Grid Service Architecture (OGSA), которая рассматривает сервис (службу) в качестве основного объекта Грид [4]. Таким образом, любое ПО в GRID-среде, должно являться доступным по сети компонентом Грид-службы (сервисом), обеспечивающим требуемую функциональность. Грид-службы могут быть как статическими, так и создаваться динамически и, согласно OGSA, обладают состоянием — набором данных, ассоциированных со службой, что позволяет различать экземпляры служб в распределенной Грид-среде.
Посредством удаленного обращения к активностям (activities) сервиса потребитель получает определенный вид обслуживания, в том числе информационного обслуживания. Элементарными программными блоками являются базовые службы, которые служат фундаментом для конструирования высокоуровневых служб. Такой подход к описанию служб и протоколов взаимодействия между ними обеспечивает высокую степень виртуализации такой абстракции как Грид-служба и обеспечивает независимость от формы реализации служб, то есть интероперабельность к среде исполнения.
OGSA позволяет создавать и управлять временными экземплярами служб, что, в свою очередь, позволяет разработчикам конструировать службы сколь угодно высокого уровня, причем платформонезависимые. На усмотрение разработчика остаются вопросы выполнения обслуживания, подготовки программного кода и реализации алгоритмов, использования языков программирования. При этом правила взаимодействия, так же как и семантика, не зависят от исполнительной среды и Web-инфраструктуры, над которой фиксируются описания состояний экземпляров служб.
И, наконец, может быть самое главное достоинство Грид-подхода, ориентированного на OGSA — стремление к максимальной стандартизации и фиксации протоколов различного уровня. И, что важно, благодаря таким сообществам, как Global Grid Forum (GGF) Грид-компьютинг располагает действенным механизмом для уточнения существующих стандартов и создания новых.
С практической же стороны, очень важным является и наличие ставшего де-факто стандартом открытого программного обеспечения Globus Toolkit. (GT) (http://globus.org/toolkit/docs/4.0/). Компоненты этого программного обеспечения среднего уровня (middleware) являются Грид-службами, разработанными в соответствии с OGSA и обеспечивающими базовую функциональность.
Пространства данных — новые вызовы
и новые информационные
службы
Важно заметить, что Грид-среда ВО заведомо более сложна, чем например Р2Р системы, не имеющие компонента централизованного управления. Именно поэтому в middleware Грид-систем такое значение уделяется безопасности и средствам управления ресурсами, а также планированию рабочей нагрузки.
А как работать с пространствами данных в ВО? Для поддержки ПД в [1] авторы предлагают создавать платформы поддержки пространств данных (Data Space Support Platform далее DSSP). Цель поддержки ПД состоит в обеспечении базового набора функций над всеми источниками данных и организации необходимого уровня связанности данных. DSSP, в отличие от СУБД, разворачивает набор сервисов поверх существующих систем управления данными, соблюдая при этом их потребности в автономии. На сегодняшний день реально работающих DSSP ещё нет, однако развитость современных Грид-платформ позволяет реализовать прототип DSSP уже имеющимся базовым набором сервисов. Речь идёт, прежде всего, о OGSA-DAI (http://www.ogsadai.org/) и инфраструктурных сервисах Грид-сегментов [5].
Однако, использование источников данных разной степени связанности (ПД) не перекрывает всех актуальных потребностей участников ВО. В современном мире как научном, так и социо-политическом, время актуализации информации постоянно уменьшается, особенно, если речь заходит о работе с потоковыми данными. А в современных информационных системах RSS feed’ы, media потоки, сенсорные сети являются полноправными источниками данных.
Временные издержки на структуризацию данных, их складирование в СУБД могут быть слишком велики. Время оказывается наиболее критичным параметром в информационных системах. Безусловно, хранение информации также должно присутствовать, но получать ее необходимо стремиться on-demand, а обрабатывать on-fly. Потребность в интеграции данных “нового” потокового типа обусловлена тем, что обработка этих данных on-fly диктуется их высокой степенью актуализации. И дает возможность генерации нового знания, которое продуцируется анализом динамики этих данных.
Набор базовых activities OGSA-DAI может только ограниченно работать с потоковыми данными: принимать и доставлять поток. Но этот набор можно расширять, чтобы службы поиска и запрашивания стали применимы в реальном времени к потоковым данным в DSSP построенной на базе GT4. Таким образом, можно не только создавать прототип DSSP, но и вести в рамках этой платформы постоянную распределённую работу с данными в целях информационной поддержки ВО, создавать новые информационные услуги.
Пример информационных сервисов (услуг)
в Science2.0
Виртуальная организация “Вакцины нового поколения” является крупнейшей в рамках RGRID. Именно для информационного обеспечения этой ВО разрабатываются большинство Web- и Грид-сервисов RGRID [5]. Хотя входящие в ВО-Вакцины медико-биологические учреждения являются в основном научно-исследовательскими институтами, а не клиниками, в рамках этой ВО разрабатываются не только собственно лекарственные средства, но и методы и системы проведения клинических испытаний и их оценки, а также стратегия и тактика клинического применения. Совокупность учреждений ВО представляет собой реальное медицинское сообщество, на примере которого можно отрабатывать технологии е-Медицины и е-Фармакологии в Грид-среде. Имеется большое разнообразие накопленных внутренних информационных ресурсов, используются также и внешние ресурсы (Медлайн, SWISS-PROT и др.).
Вспомогательные Грид-сервисы репозитория метаописаний и онтологий [5] используются для организации информационного пространства — создания в нем специализированных информационных структур промежуточного уровня. Графическое представление предметно-ориентированных онтологий является одним из видов интерфейса для эксперта, пользующегося ресурсами RGRID.
В этой ВО крайне востребованной является услуга сбора и мониторинга данных определённой понятийной направленности. Эта услуга задаётся семантической схемой — метамоделью (см. рис. 1), опирающейся на базовую онтологию некоторой отрасли знаний. В приведённом примере используется элемент базовой медицинской онтологии, однако заметим, что могут использоваться и более привычные мета-описания, например тезаурусы, представленные в OWL форме, как это реализуется, например, в проекте “Библиогрид” [6].
<Drug Name>
<Adverse
Event>
<Risk Factor
>
<Risk Probability
>
<Patient
Data>
…
</Patient Data
>
</Risk Probability
>
</Risk Factor >
</Adverse Event>
<URI > http://www....
</URI >
Рис.1
Приведённая на рис.1 метамодель предусматривает задание наименования препарата (DrugName), конкретного побочного эффекта (AdverseEvent), фактора риска (RiskFactor) и вероятности осложнения (Risk Probability). Базовый набор данных для такой модели содержится в описании препарата в Регистре лекарственных средств. Например, для побочных эффектов при применении варфарина описаны следующие основные побочные эффекты: кровотечение (bleeding), дисфункция печени (liver disfunction), диарея (diarea), некроз кожи (skin necrosis). Основные факторы риска, как правило, также известны. Например, для варфарина это возраст, артериальная гипертензия, дисфункция почек или печени.
Рис.2
Поскольку целью сбора, интеграции и представления информации пользователю является персонализация знаний о клиническом применении лекарственных препаратов, то найденный информационный объект должен включать данные о параметрах пациента или выборки пациентов, для которых получены эти данные. Часть этих и других дополнительных данных в целях упрощения изложения не приводятся. На рис. 2 показан пример информационного объекта, включающего параметрические данные, полученные в результате анализа одной из статей, посвященных опыту клинического применения варфарина при антикоагуляционной терапии и возникших при этом побочных эффектах.
Основной особенностью поисковой части сервиса следует считать необходимость постоянной актуализации и пополнения той информации, которая соответствует метамодели (см. рис. 1). В этом смысле сервис исполняет роль агента, следящего за возможными источниками в ПД ВО, Интернете и в доступных корпоративных информационных системах. Информационные объекты, выделенные сервисами лексического анализа из данных, найденных поисковыми сервисами в информационном пространстве в соответствии с заданной метамоделью, сохраняются в репозитории и могут в любой момент быть доступны участнику ВО.
Заметим, что если бы в исходной модели мы не указали бы тега “вероятность риска”, то количество собранных информационных объектов было бы много шире. Там присутствовали бы описания, типа приведённых на рис.3, в которых присутствуют выдержки их информационных источников.

Рис.3
Таким образом, вы, не приобретая никакого программного обеспечения, не используя для поиска, лексического анализа и отбора информации свой персональный компьютер будете иметь постоянный информационный поток, соответствующий заданной модели. Вместе с результирующими данными к вам придут и настроечные скрипты, позволяющие использовать либо браузер, либо экранный редактор в качестве средства визуализации. Пример визуализации при помощи браузера см. рис.4.
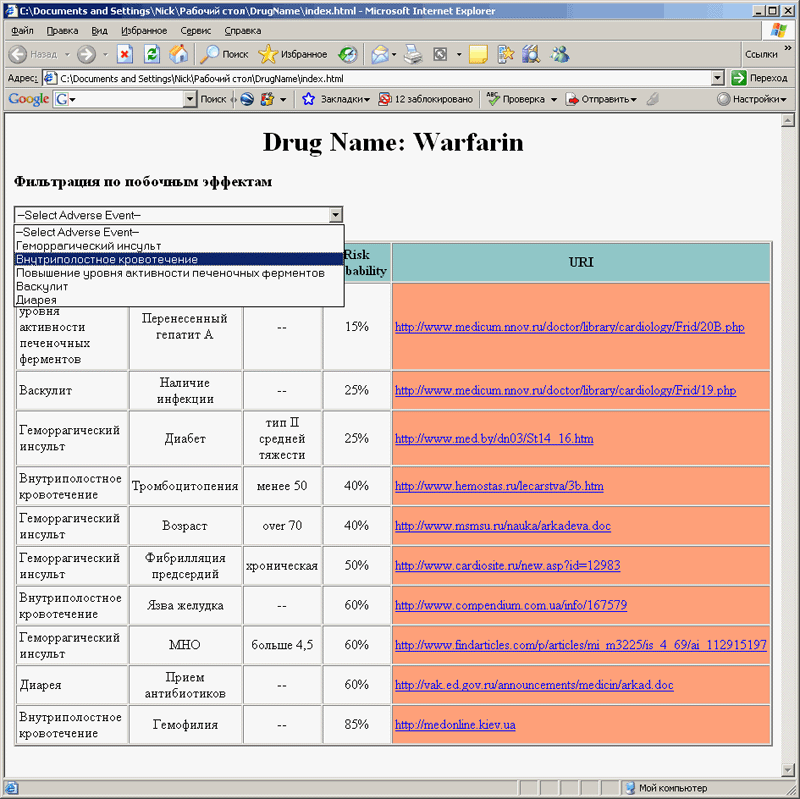
Рис.4
Вы можете организовать несколько потоков. Информацию о новинках в потоках вы можете получать, например, в специальных окнах своего браузера, которые часто используются под рекламу.
Несложно сделать новые услуги, старые приложения доступными как сервис, гораздо сложнее договориться о стандартах взаимодействия таких сервисов, преодолеть психологические барьеры. Дело доходит до того, что для сервис-провайдеров стало даже технологически выгодным маскировать новые решения под старые. Кроме того, нельзя игнорировать и элемент ответственности сервис-провайдеров перед потребителем информации. Впрочем, тут уже существует устоявшаяся практика заключения Соглашений об уровне обслуживания (SLA), что, конечно, не исключает необходимости наличия надёжных каналов связи.
Описанный подход в полной мере соответствует концепции “услуги по заказу” (On demand). При работе с такими услугами важно не забывать, что этот подход, позволяющий платить за ресурс по мере необходимости, предусматривает и необходимость дезактивации таких сервисов. IBM, активно развивающая такой подход, предлагает сейчас два варианта услуги: upgrade on demand, когда можно наращивать производительность по мере необходимости, и capacity On/Off on demand — включение/выключение требуемых ресурсов.
Заключение
Известно, что жизненно важным фактором научно-исследовательского процесса является механизм распространения знаний — чем более эффективно вы можете обеспечить разделяемый доступ не только к большим объёмам информации, но также и к ресурсам, которые используются для создания этой информации, тем более высокий уровень качества исследований и сотрудничества вы достигнете.
В грядущей Science2.0 различные источники данных совместно с приложениями в форме высокоуровневых сервисов, опирающиеся на более мелкие разноуровневые сервисы программного обеспечения среднего уровня, будут предоставляться как новые услуги, и при этом очень широко. Платформы поддержки пространств данных, реализованные на базе Грид-сегментов, уже сегодня позволяют создавать такие услуги и могут являться хорошим полигоном для дальнейших исследований.
Литература