Интеграция и загрузка структурированных данных в ИС на основе платформы ИСИР
Аджиев А.С.Введение
Одной из важнейших проблем, возникающих при организации работы информационной системы (ИС), является ее наполнение данными. При этом, как правило, структура (схема данных, онтология) репозитория ИС отличается от структуры данных, вводимых в систему. Иногда структура данных вообще не известна априори (полуструктурированные данные). Однако в большинстве ИС обычно загружается информация с известной структурой. Как правило, это структурированный текст, семантика компонентов структуры которого априори известна. Структура такого текста – однородная последовательность групп связанных ресурсов. Например, последовательность публикаций с указанием авторов, или последовательность организаций с указанием сотрудников. Структуру каждой такой группы будем называть структурой источника данных, а соответствующую ему онтологию – онтологией источника или исходной онтологией. Онтологию целевого репозитория будем называть целевой онтологией.
Как правило, для ИС существует несколько источников данных. Это могут быть другие ИС, базы данных, интерактивные вводы пользователей и другие. Информация может грузиться в пакетном режиме или вводиться интерактивно прямо в базу знаний ИС. В обоих случаях помимо задачи преобразования данных и их интеграции часто возникают также задачи исправления ошибок в них, а также контроль их адекватности оператором. Решение этих задач может быть осуществлено, как в процессе модификации базы, так и потом, в режиме "наведения порядка в ИС".
Для каждого источника данных решение всех трех задач, как правило, индивидуально. Однако решение отдельных подзадач часто более универсально и может быть применено для нескольких разных источников (например, поставляющих в ИС ресурсы одного и того же типа, и др.). Создаваемая подсистема призвана решать эти задачи.
Постановка и анализ задачи
Архитектура ИС на основе ИСИР
Интегрированная система информационных ресурсов (ИСИР) [5] – универсальная платформа для построения информационных систем и порталов. В основе любой ИСИР-системы лежит объектная модель данных, представленная как OWL-онтология (в более ранних версиях – RDFS-схема). Код прикладной логики ИС также работает с объектными данными, представленными в формате RDF, либо в виде эквивалентной структуры JavaBean классов. Фактически данные хранятся в хранилище более простой структуры (обычно реляционная СУБД), скрытом от прикладного кода ИС. Платформа ИСИР предоставляет также средства аудита объектов и разграничения прав доступа к ним для разных клиентов. OWL-онтология [6] ИС является целевой онтологией для загрузчика-интегратора.
Онтология источника данных
В соответствии с общепринятым определением, онтология [8] описывает информацию, как совокупность связанных между собою информационных ресурсов, структура которой удовлетворяет заданным ограничениям. Будем считать, что в репозитории ИС и загружаемых данных каждому ресурсу соответствует один объект реального мира из предметной области ИС. Причем, в загружаемых данных одному объекту реального мира может соответствовать несколько информационных ресурсов (имеются дубликаты), а в целевом репозитории ИС – только один.
При интеграции происходит преобразование информации от исходной онтологии к целевой. Обе эти онтологии (их части, описывающие структуру загружаемых данных) описывают одну предметную область и содержат классы и связи, имеющие сходную семантику. В процессе преобразования новые объекты и связи данных в целевой онтологии вычисляются по объектам и связям загружаемых данных.
Будем исходить из ситуации, когда загружаемые данные заданы как структурированный текст, где каждый синтаксический элемент соответствует некоторому классу онтологии источника, а синтаксические связи и пути между синтаксическими элементами соответствуют связям онтологии источника. Таким образом, онтология источника в нашем случае является концептуальной схемой данных, включающей словарь классов объектов и возможных бинарных отношений с известной семантикой. База знаний, определенная синтаксической структурой, выражена в виде дерева, выделяется средствами синтаксического анализа и представляется как XML-документ.
Связи могут быть выражены не только синтаксически, но и ссылками на объект связи (здесь понятия “связь”, “объект” и “субъект” мы понимаем в смысле RDF [7]). Эта ситуация возникает, например, при преобразовании в дерево и сериализации графовых структур, обычно применяемой в репликации данных между разными базами данных и ИС (например – XML-представление RDF-графа базы знаний, где для ссылки используется атрибут rdf:resource). В таких случаях считаем, что в исходной онтологии такое описание связи в загружаемых данных соответствует не только связи, но и ресурсу – объекту связи. Поскольку в загружаемых данных мы допускаем дубликаты, то ограничение, что связями исходной онтологии являются лишь синтаксические связи в структуре текста, не сужает класс решаемых задач.
Таким образом, без ограничения общности считаем, что на входе загрузчика имеем XML-текст с известной структурой и семантикой ее элементов, которую и рассматриваем как исходную концептуальную схему или онтологию.
Проблемы, возникающие при преобразовании данных, классификация ошибок и конфликтов
Как правило, между исходной и целевой онтологиями нельзя установить взаимно однозначного соответствия по семантике понятий и связей (иначе концептуальные схемы данных совпали бы, и преобразование данных не потребовалось). Обычно существуют различия – конфликты схем данных [1,2].
В наиболее общем виде объекты и связи целевой онтологии представимы как функции от объектов и связей в онтологии источника данных. Такие функции принимают на входе и выдают коллекции из объектов и связей каждого типа. Например, связи представимы как булевские функции, показывающие, есть ли между заданными объектами связь заданного типа. Можно построить преобразователь данных, в котором эти функции будут реализованы на алгоритмическом языке (Java). Но такие функции не могут обладать даже минимальной универсальностью, так как должны быть переписаны даже при незначительных изменениях задачи.
Все классы и связи целевой онтологии имеют свои прототипы в исходной онтологии (классы и связи, по экземплярам которых они вычисляются). Будем считать, что для любых двух ресурсов, связанных между собою в целевой онтологии, можно указать в исходной онтологии соответствующие пути от ресурсов – прототипов субъекта связи, к ресурсам – прототипам объекта связи, и это Xpath-пути в XML-представлении загружаемых данных. Сформулированное ограничение несколько сужает класс задач, решаемых загрузчиком-интегратором. Например, если исходные данные - персоны с указанием возраста, а в репозитории ИС надо проставить связи между теми из них, кто имеет одинаковый возраст – такая задача не входит в рассматриваемый класс задач (указанная связь не имеет прототипа).
Многие исследователи, в соответствии со своими потребностями, давали разные классификации конфликтов онтологий (например [1, 2 и 3]). Все эти классификации выделяли, в целом, сходные наборы конфликтов. Применительно к сформулированной выше задаче интеграции на основе существующих работ можно выделить следующий перечень конфликтов:
Описанная выше классификация построена на основе классификаций, предложенных в [1,2], из которых были удалены конфликты имен (поскольку исходная онтология является по условию известной), а также обобщены некоторые классы конфликтов.
Помимо конфликтов схем, на практике часто встречаются также ошибки данных. Их можно разделить на ошибки значений, и семантические ошибки. В ошибки значений атомарных атрибутов входят опечатки и отклонения формата значения атрибута от декларированного в исходной онтологии. Их можно обнаружить и исправить при интеграции. Мы не рассматриваем ошибки "объектных атрибутов", т.е. несоответствия входных данных ограничениям исходной онтологии, поскольку по условию задачи семантика входных данных интерпретируется в соответствии с заданной априори схемой.
К семантическим будем относить ошибки, когда фактическая семантика отдельных объектов не соответствует декларируемой для нее в исходной онтологии. Например, когда вместо фамилии персоны написано отчество. По сути, такие ошибки можно рассматривать как частный случай семантических конфликтов, или как особенность онтологии источника.
Принятие недостоверных решений, роль эксперта
Решение задачи интеграции можно рассматривать как объединенную онтологию, включающую в себя исходную и целевую онтологии, а также, как дополнительные ограничения целостности, правила (алгоритмы) преобразования знаний из исходной онтологии в целевую. Загрузчик-интегратор можно рассматривать как агент, осуществляющий необходимый логический вывод в этой онтологии на имеющейся объединенной базе знаний. Можно выделить 2 типа правил преобразования:
Правила, формулируемые в терминах обрабатываемых знаний, на основе описанной выше классификации конфликтов можно разбить на 6 подтипов:
По условию постановки задачи и ограничений, наложенных на исходную онтологию, правила первого типа могут быть формально заданы на одном из языков преобразования объектных данных, например, XSLT. Правила второго типа формализовать сложнее. Они не всегда могут быть заданы как машинно-выполнимые алгоритмы, и часто требуют информацию, не содержащуюся в объединенной базе знаний, то есть внесение информации извне (например, вопрос к эксперту). Будем называть результаты, выдаваемые такими правилами, недостоверными решениями.
Недостоверные решения могут приниматься специальными алгоритмическими модулями, которые выносят решение на основе анализа данных, статистики предыдущих сеансов загрузки, мнения человека-эксперта и других факторов. В последнем случае модуль использует специальный пользовательский интерфейс, который предоставляет эксперту всю необходимую информацию для принятия решения.
Архитектура загрузчика-интегратора
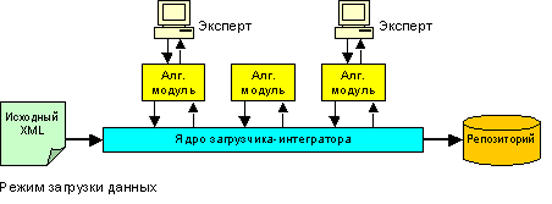
Создаваемый загрузчик-интегратор должен осуществлять пакетную загрузку данных в ИС из файла, содержащего однородную последовательность групп связанных ресурсов, т.е. должен циклически обрабатывать все такие группы. Алгоритмические модули принятия недостоверных решений в простых случаях принимают решения самостоятельно, и лишь в сложных обращаются к эксперту. При этом циклическая обработка приостанавливается до получения от эксперта ответа.
Модульный принцип построения
Описываемая архитектура загрузчика-интегратора является единой для всех возможных источников данных рассматриваемого класса и всех целевых ИС. Но каждый алгоритмический модуль, реализующий конкретное правило преобразования, зависит от конкретной задачи. Однако некоторые, в особенности, простые алгоритмические модули, могут применяться, хотя и не во всех, но в достаточно широкому кругу задач. Таким образом, загрузчик-интегратор создается на основе общего ядра, реализующего алгоритмы, не зависящие от конкретной онтологии или правил (главный цикл обработки, логический вывод на онтологии, средства построения интерфейсов экспертом и др.), а также реализующих специфические правила алгоритмических модулей, с которыми ядро взаимодействует на основе стандартных интерфейсов. Многие модули могут быть представлены как композиции таких элементарных модулей. Например, строка, содержащая список телефонных номеров, может быть сначала разбита модулем разбиения на отдельные подстроки-номера, а затем каждый номер приведен к установленному формату другим модулем. Для ИС с большим количеством источников данных имеет смысл создание библиотеки алгоритмических модулей, использующихся в разных задачах.
Процесс нормализации, преобразования, интеграции и загрузки данных, шестишаговая архитектура
Существуют следующие взаимосвязи, ограничивающие порядок решения разных подзадач при интеграции и загрузке данных:
С учетом сформулированных выше требований, обработка может быть разбита на 6 стадий, образующих шестишаговую архитектуру загрузчика-интегратора, и организована в виде потока работ:
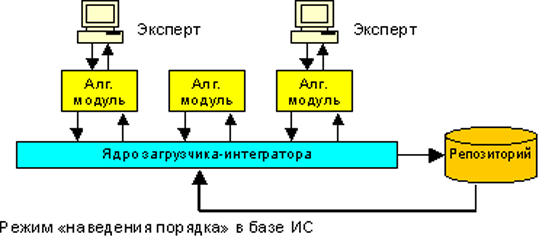
На стадиях 4, 5 и 6 ведется работа с данными, находящимися в хранилище. Модули стадии 1, нормализующие атомарные атрибуты, могут работать с данными, как в исходном XML, так и в хранилище. Возможна работа без стадий 2 и 3, для нормализации, удаления дубликатов и устранения конфликтов целостности в репозитории, то есть в режиме "наведения порядка". В этом случае обработке подвергаются все хранимые в системе данные.
Разделение стадий 1 и 2 условно, поскольку реализующие их алгоритмические модули работают одновременно, как единая стадия преобразования данных и исправления ошибок. Сама единая стадия может быть разбита на несколько шагов, в каждом из которых исправляется часть ошибок и преобразуется часть данных. Это позволит разнести по времени труд экспертов, исправляющих разные ошибки. Промежуточные результаты работы этих шагов будем называть промежуточным XML.
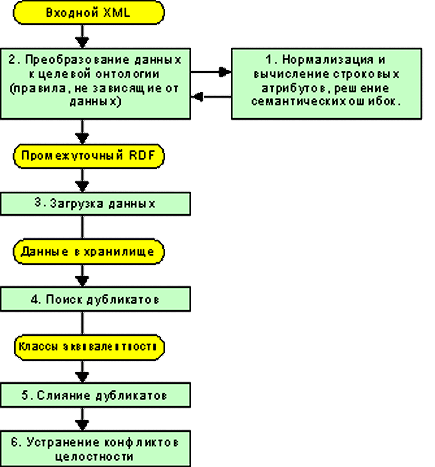
Результатом работы первой и второй стадий будет промежуточный RDF – RDF-текст, обладающий следующими свойствами:
Рассмотрим пример, показывающий необходимость в промежуточном RDF дополнительной информации, а также иллюстрирующий работу загрузчика-интегратора (на рисунке ниже). На загрузку подаются XML-описания персон и организаций. Описания организаций содержат список должностей и ИНН занимающих их персон, а также адрес организации. Описания персон содержат имена и ИНН. Целевая онтология предусматривает хранение персон с именами и адресами мест их работы, и не включает ИНН. После преобразования данных промежуточный RDF будет содержать для каждой персоны несколько дубликатов. Все они на пятой стадии сливаются в один ресурс. Единственный способ распознать потом дубликаты – сопоставить их ИНН.
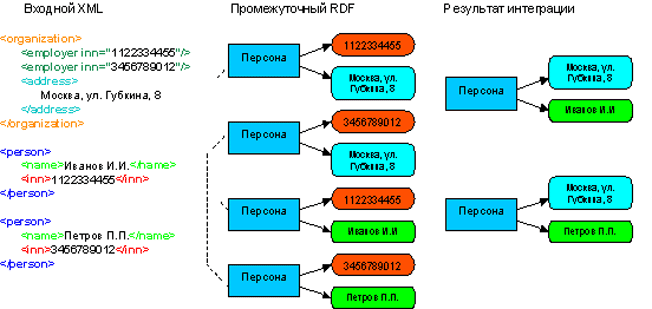
Работа модулей принятия недостоверных решений и вмешательство экспертов необходимы только на первой, четвертой, пятой и шестой стадиях. Кроме того, при построении загрузчика-интегратора иногда технически возможно и оправдано решать задачи одних стадий на других стадиях. Например, некоторые простейшие задачи нормализации, уточнения семантики и слияния дубликатов, не требующие вмешательства эксперта, могут быть выполнены на второй стадии средствами XSLT.
Первая и вторая стадии. Преобразование данных, нормализация и вычисление атомарных атрибутов, решение семантических конфликтов
Единицей обработки для загрузчика-интегратора на этих стадиях является группа связанных между собою ресурсов. Преобразование данных задается в терминах XSLT, как универсального языка, позволяющего задавать практически любые требуемые преобразования XML-данных. XSLT значительно удобнее для этих целей, чем алгоритмический язык. Однако для исключения возможных ограничений на класс решаемых задач допускается написание преобразователя, работающего с DOM-моделью текущей группы ресурсов на Java.
Алгоритмические модули принятия недостоверных решений решают на первой стадии конфликты первых трех типов: исправление ошибок и нормализация атомарных атрибутов, вычисление новых атрибутов и исправление семантических ошибок и конфликтов. Решение семантических конфликтов и нормализация атомарных значений, как было показано, не могут быть в общем случае полностью разнесены во времени. Иногда частичное решение этих задач необходимо совместить в одном модуле, когда решения разнотипных конфликтов взаимозависимы (например, нормализация значения атрибута и определение его семантики).
Алгоритмические модули первого уровня реализуются как Java-классы с заданным интерфейсом. Модуль получает как параметры коллекцию вершин XML-дерева текущей группы ресурсов, и вычисляет на основе них необходимые значения. Такой подход позволяет абстрагироваться в модулях от расположения вершин в XML-дереве и использовать одни и те же модули в разных интеграторах.
В силу определения, исходная онтология и схема промежуточного XML, может иметь лишь связи вида 1:1 и 1:n (1 к многим), поскольку XML-данные имеют древовидную структуру. Однако в промежуточном RDF могут появиться также связи n:1 и m:n, что потребует генерацию дубликатов. Для этих целей имеется встроенный механизм генерации уникальных URI для RDF-ресурсов.
Третья стадия. Загрузка данных в репозиторий ИС
Компонента 3 стадии универсальна и не зависит от решаемой задачи загрузки. Загруженные ресурсы не должны быть доступны пользователям ИС до окончания их идентификации, слияния и приведения в соответствие с ограничениями целостности.
Четвертая стадия. Идентификация загружаемых ресурсов
Перед началом работы блока идентификации определяется круг обработки. Это могут быть ресурсы, загружаемые в текущем сеансе загрузки, или все ресурсы хранилища, если интегратор работает в режиме “наведения порядка в хранилище”, т.е. устранения образовавшихся ранее дубликатов. Множество ресурсов каждого типа (класса целевой онтологии) должно быть разбито на классы эквивалентности, включающие ресурсы-дубликаты одного и того же объекта.
В качестве параметров модулю принятия недостоверных решений передается ресурс, для которого необходимо отыскать дубликаты, а также множество ресурсов, из которых он может делать выбор кандидатов в дубликаты – множество анализа. Множество может включать любые ресурсы репозитория ИС того же класса и суперклассов. На выходе модуль должен выдать подмножество множества анализа, состоящее из найденных дубликатов.
Модули идентификации можно рассматривать как правила определения дубликатов – ограничения целостности в объединенной онтологии задачи, которые определяют в ней новый тип – класс эквивалентности. Модуль должен удовлетворять следующему важному условию: решение о включении ресурса в класс эквивалентности не должно зависеть от наличия или отсутствия каких-либо других ресурсов во множестве анализа.
Модули идентификации должны быть указаны для всех типов ресурсов целевой онтологии, для которых ищутся дубликаты. Они могут быть не только сложными алгоритмами на Java, но и встроенными элементарными модулями. Например, выдающими для каждого ресурса только его самого (если никакие ресурсы не должны быть слиты между собой), или объединяющие в один класс все ресурсы, связанные с ресурсами из одного класса эквивалентности некоторой связью (например, все даты рождения одной персоны). Возможно построение композиционного модуля идентификации на основе нескольких модулей. Каждый из таких модулей может анализировать определенные атрибуты ресурса и выбирать свои кандидаты в дубликаты. С помощью заданного теоретико-множественного выражения из результатов, выданных элементарными модулями, вычисляется множество – результат композиционного модуля. Входящие в состав композиционного простые модули будут иметь более широкую применимость в разных задачах интеграции, чем сам композиционный модуль.
Модуль идентификации вызывается для каждого ресурса в кругу обработки, а также для ресурсов за пределами круга, попавших в какой-либо класс эквивалентности. Каждое множество, выдаваемое модулем, вместе с ресурсом, для которого оно вычислено, образует первичный класс эквивалентности.
При вычислении окончательного разбиения на классы эквивалентности необходимо минимизировать количество обращений к модулям принятия недостоверных решений, так как последние могут содержать сложные алгоритмы или обращаться к эксперту. Поскольку отношение принадлежности двух ресурсов к одному классу эквивалентности рефлексивно, транзитивно и симметрично, окончательное разбиение на классы с минимальным числом вызовов может быть получено следующим алгоритмом:
Легко показать, что:
Последнее означает, что если модуль обращается с вопросом к эксперту, количество указаний на дубликаты, которое придется сделать эксперту, не больше общего количества дубликатов в кругу обработки (как правило, оно меньше, так как обычно очевидные дубликаты модуль выявляет самостоятельно).
Учет ограничений целостности целевой онтологии
При идентификации и слиянии дубликатов может быть использован логический вывод из целевой онтологии, сделанный на основе ее ограничений целостности. Платформа ИСИР позволяет указывать следующие ограничения в онтологий ИС:
Ограничения первого типа в промежуточном RDF выполнены по определению. Ограничения четвертого типа сводятся к ограничениям кардинальности, если рассматривать каждое свойство типа "1 значение на язык" как совокупность нескольких (по числу возможных языков) свойств единичной кардинальности. Ограничение по зависимости объектов не может быть явно использовано при поиске дубликатов. Таким образом, на 4 стадии мы можем учитывать только ограничение кардинальности. Конкретно, это выражается в информации, является ли связь однозначной или многозначной, чтобы после разбиения на классы объекты однозначной связи субъектов из одного класса эквивалентности также лежали все в одном классе. Ограничение минимальной кардинальности, а также зависимость объектов, будут учтены на 5 и 6 стадиях.
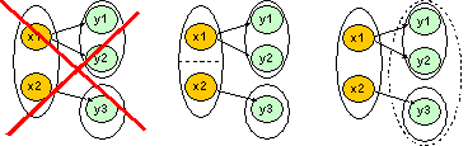
Связи между ресурсами из разных классов эквивалентности, рассматриваемые как связи между этими классами, должны удовлетворять кардинальности свойств, поскольку на 5 стадии каждый класс должен быть слит в один элемент. При независимом поиске дубликатов для разных типов ресурсов такие ограничения не будут выполнены. Необходимо изменить описанный алгоритм так, чтобы полученный набор классов удовлетворял ограничениям кардинальности.
На разбиение на классы эквивалентности могут влиять связи вида 1:1, 1:n и n:1. 2 ресурса из одного класса, находящиеся в такой связи “со стороны, противоположной единице” не могут быть связаны с ресурсами из разных классов. Существуют 2 способа решения этой проблемы:
Например, если 2 организации попали в один класс, а 2 их директора в разные, то либо 2 директора должны быть слиты в одного, либо 2 организации разнесены на 2 класса, так как не может быть 2 директора у одной организации.
Простейшим решением проблемы будет возложение на разработчиков модулей ответственности за непротиворечивость, т.е. выполнение кардинальности для классов. Это сильно усложнит разработку модулей и ограничит их применимость в других задачах. Однако этот путь также поддержан в системе.
Альтернативным, но, как показано ниже, не универсальным вариантом является использование правил разрешения конфликтов. Для этого все типы ресурсов, вовлеченные в устранение дубликатов, нужно упорядочить по приоритетности разбиения на классы эквивалентности одного над разбиением другого. В случае конфликта разбиение менее приоритетного пересматривается.
Процесс вычисление разбиений организуется как циклический обход всех вовлеченных типов ресурсов от более приоритетного к менее приоритетному, разбивая ресурсы каждого типа на классы эквивалентности. При повторном проходе каждого типа ресурсов стартовым для алгоритма является разбиение, полученное на предыдущей итерации. Циклический обход повторяется до тех пор, пока не прекратится укрупнение классов эквивалентности.
Определим правила корректировки разбиения для связей вида 1:1, 1:n и n:1:
Заметим, что в ситуации 5 алгоритм с правилами не всегда применим. 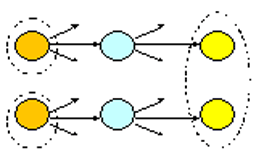 Такой
пример показан на рисунке. Здесь объекты слева и справа имеют более высокий
приоритет, чем средние. При таком соотношении классов эквивалентности любое
разбиение средних объектов будет ошибочным. Возникновение такой тупиковой
ситуации свидетельствует о неверном упорядочивании типов. Однако бывают случаи,
неразрешимые для алгоритма с правилами при любом упорядочивании.
Такой
пример показан на рисунке. Здесь объекты слева и справа имеют более высокий
приоритет, чем средние. При таком соотношении классов эквивалентности любое
разбиение средних объектов будет ошибочным. Возникновение такой тупиковой
ситуации свидетельствует о неверном упорядочивании типов. Однако бывают случаи,
неразрешимые для алгоритма с правилами при любом упорядочивании.
Необходимым для корректности разбиения с использованием правил является условие, что алгоритмические модули не используют для принятия решения о разбиении на классы эквивалентности менее приоритетных типов, или текущее разбиение этого же типа. Можно показать, что в этом случае разбиение на классы эквивалентности может быть получено за один обход всех вовлеченных типов данных (классов целевой онтологии). Когда это ограничение не выполняется (например, при репликации иерархических структур, когда необходимым условием включения ресурсов в один класс является включенность в один класс их предков по иерархии), или корректное упорядочивание по приоритетам невозможно, модуль принятия решения сам должен обеспечить выполнение кардинальности.
В силу конечности количества ресурсов в репозитории итоговое разбиение на классы эквивалентности ресурсов всех типов будет получено за конечное число итераций обхода вовлеченных типов ресурсов. Можно показать также, что на любом шаге алгоритма разбиение не противоречит ограничениям максимальной кардинальности и условиям разбиения на классы эквивалентности объединенной онтологии.
Пятая стадия. Слияние ресурсов
После разбиения ресурсов на классы эквивалентности все ресурсы каждого класса должны быть слиты в один ресурс. Слияние связей определяется слиянием ресурсов. Слияние осуществляется алгоритмическими модулями принятия недостоверных решений. Модули указываются для каждого типа ресурсов целевой онтологии. В качестве параметров модулю передается коллекция ресурсов одного класса эквивалентности. Модуль может вызывать другие алгоритмические модули слияния ресурсов для произвольных подмножеств сливаемого класса (например, встроенные модули).
Существуют встроенные алгоритмические модули, выполняющие наиболее общеупотребительные элементарные операции слияния, такие как:
При поатрибутном слиянии ресурсов для атомарных атрибутов могут быть использованы эти же встроенные модули (кроме 3 и 4). При удалении игнорируемого ресурса из хранилища удаляются также и все зависимые от него ресурсы. Это означает, что каждый шаг процедуры слияния должен начинаться с вызова модуля слияния для одного из классов эквивалентности независимых ресурсов. Дальше вызываются модули слияния для всех его зависимых ресурсов в той последовательности, как они встречаются в путях по графу зависимости.
Когда будут обработаны все классы эквивалентности независимых ресурсов, процедура слияния будет полностью завершена.
Шестая стадия. Приведение данных в соответствие с ограничениями целостности
На этой стадии данные модифицируются в соответствии со всеми ограничениями целостности, кроме ограничений максимальной кардинальности (они были выполнены на 4 стадии) и условий зависимости между ресурсами (они были выполнены на 5 стадии). Например, дописываются обязательные атрибуты. Возможные ограничения целостности, накладываемые в ИС, плохо поддаются формализации. Модули, решающие такие конфликты, последовательно вызываются в заданном порядке, и каждый из них имеет свободный доступ к хранилищу.
Заключение
Можно утверждать, что описанный выше подход к решению задачи интеграции и загрузки информации из структурированного текста в ИС с объектной структурой данных применим для решения любых задач в обозначенном в главе "Постановка задачи" классе при условии, что правила преобразования данных сформулированы описанным выше способом. Действительно, при описании работы загрузчика-интегратора на каждом уровне сначала формулировалась задача в общем виде, а затем приводилось ее решение, не ограничивающее ее общности.
Описанный подход является лишь одним из возможных. В любом случае, при построении загрузчика-интегратора для конкретного источника необходимо специфицировать правила преобразования данных, и разные подходы, по сути, определяют разные способы такой спецификации. В простейшем виде, например, спецификация выражается в программном коде загрузчика, написанном "с нуля" для конкретной задачи. В описанном выше подходе это XSLT-таблица преобразования данных и набор алгоритмических модулей, содержащих, по возможности, алгоритмы – ответы на простые вопросы "как решить ту или иную подзадачу?". Простота вопросов определяет их универсальность, то есть применимость одного решения в разных задачах.
В настоящий момент в рамках проекта ИСИР разрабатывается подсистема, реализующая описанный выше подход.
Литература