Схемы метаданных ЕНИП:
практика применения OWL в ЕНИП
Работа посвящена схемам метаданных Единого Научного Информационного Пространства РАН, применение которых должно сыграть ключевую роль в обеспечении семантической интероперабельности в научной среде РАН, упрощении обмена и взаимодействия информационных систем, входящих в ЕНИП. В работе поясняются основные цели и принципы формирования модульных схем ЕНИП, применение языка OWL для описания схем. Даётся обзор базового набора схем ЕНИП, отвечающего за описание научной информации общего характера, а также упоминаются основные разработанные специализации, отвечающие более специфическим научным областям. Данная статья дает лишь краткий обзор предложений по метаданным ЕНИП, более подробная исчерпывающая информация и пояснение способа формирования RDF/XML-документов в соответствие со схемами ЕНИП приведены в издаваемом отдельно Руководстве по схемам метаданных ЕНИП.
Роль схем метаданных ЕНИП
Единое Научное Информационное Пространство РАН (ЕНИП РАН) – это инициатива, ставящая своей задачей интеграцию научных данных различных учреждений РАН и построение единой распределенной среды с целью обеспечения активных научных коммуникаций и эффективного использования научной информации, более эффективных средств поиска информации, сотрудничества и совместной работы. Подробнее о целях, задачах и средствах ЕНИП см. [1, 2].
Для формирования масштабной распределённой среды, интеграции многих независимых информационных систем, наилучшим вариантом проведения интеграции является обеспечение “свободного общения”, “взаимопонимания” этих систем – так называемой интероперабельности систем. Интероперабельность – это способность системы к взаимодействию с другими системами. Под этим понимается соблюдение определенных правил или привлечение дополнительных программных средств, обеспечивающих возможность взаимодействия независимо разработанных программных систем. Это своего рода стандарты, которым должны удовлетворять интегрируемые информационные системы.
Принято различать три уровня интероперабельности информационных систем – техническую, синтаксическую и семантическую, которым соответствуют транспортная среда, формат сообщений и смысл данных. В данной статье мы сфокусируемся на проблеме семантической интероперабельности. Это термин, появившийся сравнительно недавно, уже после того, как XML стал де-факто стандартом представления данных при обмене, что дало возможность гарантировать синтаксическую интероперабельность в Web и рассмотреть более сложные проблемы идентификации семантики, смысла данных помимо просто их структуры. Семантическая интероперабельность – это способность приложений понять смысл данных друг друга.
Данные могут относиться к различным предметным областям, в рамках одной иметь разные выражение и интерпретацию. Соответственно, для обеспечения семантической интероперабельности, во-первых, необходим некоторый механизм, позволяющий описать предметную область, указать, какие в ней используются термины и как они взаимосвязаны – схему данных. Таким общим механизмом является стек технологий Semantic Web: RDF, RDFS, OWL. В данной работе мы не будем подробно рассматривать эти технологии (см. спецификации [3,4]).
Во-вторых, необходим некоторый набор стандартов-схем метаданных, описывающих общепринятые понятия, которыми будут “общаться” интегрируемые системы. В рамках ЕНИП – это набор базовых схем для описания научной информации, такой как публикации и разработки, и пр. – “толковый словарь” для общения научных ИС. Именно этим схемам и посвящена данная статья. Дальнейшие разделы рассматривают состав предложений по формированию набора элементов метаданных ЕНИП и принципы структуризации элементов метаданных.
Лежащие в основе предложений ЕНИП стандарты и работы
В настоящее время заметна широкая тенденция по стандартизации RDF-словарей элементов метаданных для конкретных предметных областей – так называемых “обменных схем”. Использование терминов (свойств, словарей значений и пр.), зафиксированных в стандартах, позволяет приложениям легко интегрироваться между собой, обмениваться информацией, понятной им всем. Например, при получении данных из сторонней системы, приложение может найти среди неизвестных ему свойств некоторые свойства, регламентированные стандартом, и соответственно будет уверено в их смысле, семантике, сможет правильно их проинтерпретировать. Это и называется “семантической интероперабельностью”.
Dublin Core Metadata Initiative (DCMI) определил минимальный набор свойств для описания цифровых ресурсов Web, а также их детализацию в рамках “общего профиля” [6]. Отдельные рабочие группы DCMI занимаются стандартизацией более специализированных профилей метаданных таких предметных областей, как библиотечная информация [7], образование [8], правительственная сфера [9], информация о людях [10] и пр.
Dublin Core стал базисом для других “стандартов обмена”. В первую очередь, следует упомянуть стандарт Publishing Requirements for Industry Standard Metadata (PRISM) [11], разработанный издательскими организациями для обмена метаданными о публикациях (документах, журналах, книгах и пр.). Государственный архив Австралии выдвинул и стандартизовал основанный на Dublin Core набор профилей метаданных для описания государственной информации – AGLS Metadata Standard [12]. Заслуживают упоминания также проекты, делающие попытку спецификации схем для библиографической информации (BIBLINK [15], bibTeX [16]…), европейская инициатива по разработке схем для Math-Net [17], UKOLN RSLP CLD [18] профиль метаданных для описания цифровых коллекций и пр. Широкое применение нашли предложения по представлению информации стандарта VCard (“визитная карточка”) в RDF [13]. VCard определяет свойства для описания информации о людях, их контактной информации и пр. На описание информации о людях направлена также набирающая популярность открытая инициатива Friend of a Friend (FOAF) [14].
Помимо обменных “профилей метаданных”, существуют инициативы по построению “онтологий” предметных областей, нацеленных больше на спецификацию большого количества классов и их взаимоотношений, нежели словарей свойств для обмена. Среди них: KA2 - Knowledge Acquisition Community Ontology [20] и SWRC - Semantic Web Research Community Ontology [21]. Эти онтологии описывают персоналии, организации, проекты, публикации и пр. Из последних Semantic Web-разработок в этой области следует упомянуть онтологию портала Advanced Knowledge Technologies (AKT) - "AKTive Portal" [19].
При разработке предложений по наборам элементов метаданных ЕНИП мы провели детальный анализ всех упомянутых и других (daml.org, protege.stanford.edu,…) стандартов и предложений, а также анализ различных не-RDF ориентированных предложений по стандартизации метаданных (CERIF 2000 [22], CIDOC [23], MARC и RUSMARC и др.), различных отечественных и международных систем классификации ресурсов. Основные международные стандарты и предложения были непосредственно включены в предложения ЕНИП, в частности, Dublin Core, vCard, а также FOAF, UKOLN RSLP CLD.
Кроме того, мы основывались на нашем опыте в разработке и поддержке информационного портала РАН (http://www.ras.ru), а также нашем опыте в разработке информационных систем, в частности, портала научного института ВЦ РАН, включая субпорталы электронной библиотеки, каталога научной информации, библиотечного отдела [26], редакционно-издательского отдела, портала mathnet [27], системы ведения конференций [28] и портала научного института ПНЦ РАН, тематическому порталу “Сверхпроводимость”, системе каталогизации экспериментальных данных научных исследований ТОИ ДВО РАН [29], портала инновационной деятельности [24], электронной библиотеки диссертаций РГБ [25], информационного портала ГСНТИ, официального портала ВМиК МГУ (http://cmc.msu.ru) и пр.
Авторы статьи выражают благодарность нашим коллегам, участвовавшим в обсуждении и формировании предложений по схемам метаданных ЕНИП, в частности, Каленову Н.Е. (БЕН РАН), при существенной поддержке которого был сформирован профиль библиографической информации ЕНИП, Алексееву А.Н. (ИМСС УрО РАН), участвовавшему в обсуждении схемы описания конференций и предложившему схему поддержки проведения конференций, Аджиеву А.С. (ЦНТК РАН), предложившему схемы математической информации и тезаурусов, а также другим нашим коллегам, участвовавшим в обсуждении предложений ЕНИП.
Обзор состава предложений ЕНИП
Естественно, информационное наполнение Единого Научного Информационного Пространства на начальном этапе поддержки ЕНИП не может представлять всего разнообразия тематической специализации различных научных учреждений. Необходимо представить в первую очередь информацию, характеризующую основные аспекты научной деятельности. Соответственно, во-первых, должен быть выделен основной профиль метаданных ЕНИП, включающий общеприменимые и первоочередные предметные области, независимо от тематической специализации отраслей науки. Во-вторых, должен быть специфицирован механизм расширения стандарта дополнительными специализированными профилями, ориентированными на использование в специализированных научных сообществах, а также может быть предложен ряд наиболее существенных специализированных профилей.
В основной профиль можно выделить общую поддержку следующих четырех основных групп информационных сущностей:
Основной профиль метаданных ЕНИП подробно описан далее в данной статье. Основной профиль опирается на выделяемые в отдельный профиль вспомогательные схемы, которые включают общую поддержку контролируемых словарей, классификаторов и тезаурусов; поддержку конкретных типов справочников: геополитических единиц и административно-территориального деления, национальных языков; общую поддержку контактной информации.
Помимо базового набора элементов метаданных, предложения ЕНИП включают ряд наиболее существенных специализированных/прикладных профилей метаданных; в настоящее время публикуются следующие специализации:
Структурная организация элементов метаданных ЕНИП
Предложения по наборам элементов метаданных ЕНИП являются развитием идей Dublin Core Metadata Initiative (DCMI) в направлении дальнейшей детализации наборов элементов метаданных в направлении различных предметных областей, имеющих отношение к научным исследованиям, с целью поддержки обмена как метаданными общего характера в рамках всего научного сообщества, так и более узкоспециализированными метаданными в рамках заинтересованных сообществ (например, библиотечного, математического, музейного сообщества).
В отличие от предложений Dublin Core Metadata Terms [6], которые содержат достаточно небольшой набор общих элементов метаданных, нацеленных в основе своей на описание web-документов, структура предложений ЕНИП охватывает существенно более широкий набор понятий и позволяет в зависимости от нужд приложения описывать их на существенно более высоком уровне детальности. Соответственно, встает задача структурной организации элементов метаданных ЕНИП, выделения отдельных профилей, специализаций, подсхем, уровней детальности описания. Текущие разработки дополнительных элементов метаданных DCMI [7,8,9,10] также нацелены на описание более конкретных предметных областей, соответственно, для них вводится понятие профилей приложений (Application Profiles), которые решают такую задачу в рамках предложений DCMI. Профиль приложения состоит из элементов, взятых из одной или нескольких схем стандартов, объявляющих термины, и собранных вместе для нужд конкретного приложения (в частности, конкретного сообщества). Профиль приложения позволяет определить, какие из элементов стандарта (или нескольких стандартов) нужны для решения задач данного приложения, то есть, как данное приложение использует стандарт.
Понятие профиля приложения в том виде, в каком оно рассматривается DCMI, пригодно, опять же, только для ограниченных наборов поверхностных метаданных общего характера, предлагаемых стандартами DCMI, и не затрагивает вопроса различных уровней поддержки детализации метаданных разными приложениями. Для предложений ЕНИП необходимо более развитое решение.
Кроме того, предложения DCMI не рассматривают онтологического аспекта описания метаданных – классов. DCMI определяет допустимые к применению поля (свойства) метаданных и варианты их значений, но не указывает типов ресурсов (классов), к которым эти относятся свойства, поскольку все предложения DCMI в большей мере нацелены лишь на описание web-документов, в наиболее широком смысле – на описание разработок/продуктов. DCMI не определяет, как описывать людей и организации, разного рода деятельность – проекты, мероприятия, и пр. Предложения ЕНИП затрагивают все эти и некоторые другие предметные области, и, соответственно, определяют не только свойства, но и классы метаданных.
Наконец, существующие предложения по представлению элементов Dublin Core в RDF/XML опираются лишь на понятия языка RDF Schema (RDFS [3]), с целью фиксации словарей элементов метаданных (свойств и типов значений), но не определяя ограничений на применение этих свойств, равно как и классов, к которым они относятся. Предложения ЕНИП затрагивают эти вопросы и другие аспекты построения онтологии каждой предметной области, а не просто спецификации набора терминов стандарта. Соответственно, для описания элементов метаданных ЕНИП используется подмножество языка описания Web-онтологий OWL [4].
Как следствие указанных требований, с целью структурной организации элементов метаданных ЕНИП вводится понятие “OWL-схемы блока ЕНИП”. Определение и описание всех элементов метаданных ЕНИП разбивается на отдельные схемы-фрагменты, каждая из которых вводит дополнительные понятия, либо уточняет понятия других схем.
Таким образом, элементы метаданных ЕНИП разбиваются на множество схем опциональных для поддержки в конкретных приложениях. Каждое приложение в ЕНИП может описать собственный профиль приложения, указывая набор поддерживаемых этим приложением схем, то есть, обеспечивается индивидуальный для каждого приложения уровень поддержки стандартов ЕНИП.
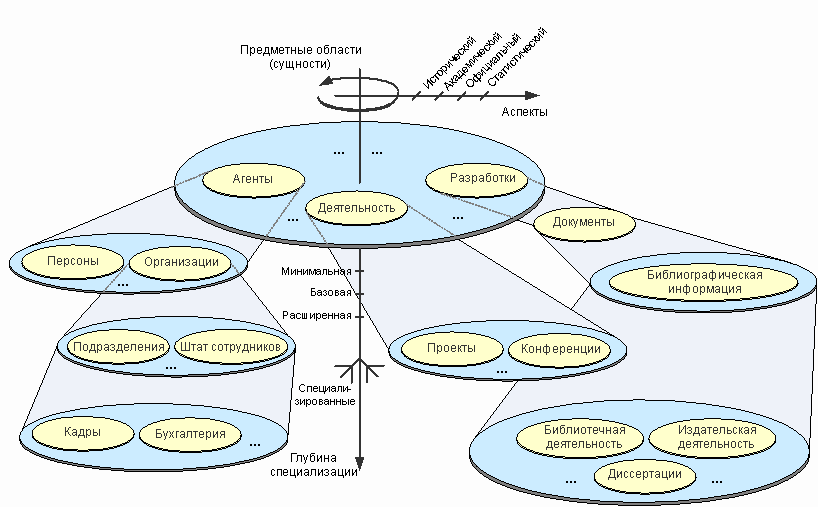
Элементы метаданных ЕНИП подразделяются на отдельные схемы по нескольким направлениям (рис. 1):
Рис. 1. Способ структурной организации элементов метаданных ЕНИП
Последовательно расшифруем эти направления. Во-первых, различные информационные системы могут ориентироваться на различные предметные области. Например, одни имеют дело с научными публикациями, другие с проектами, третьи и с тем, и с другим. Соответственно, желательно иметь как минимум отдельную схему под каждую “минимальную предметную область”, чтобы тематически разделить элементы метаданных, а также предоставить каждому приложению возможность выбора набора необходимых ему предметных областей. Помимо содержательных предметных областей выделяются так называемые вспомогательные схемы, не несущие прямой смысловой нагрузки, но используемые в качестве необходимых элементов описания основных схем.
Наряду с выделением общих предметных областей, делается попытка определиться со стратегиями, методиками развития схем – наращивания уровней, глубины описания той или иной предметной области, подходящих для разных систем. Необходимо не просто предложить схему для той или иной сущности или научной области, но и для каждой из них предложить несколько “уровней поддержки” этой предметной области разными системами. Так, по полноте описания конкретной предметной области отдельные схемы ЕНИП, как правило, подразделяются на следующие уровни:
Дальнейшее наращивание глубины описания предметной области подразумевает переход к специализации предметной области, как правило, в нескольких направлениях. Термины, определяемые специализированными схемами, ориентированы в основном на обмен метаданными в рамках специализированных научных сообществ, на работу специалистов в данной отрасли. Например, поддержка библиографического описания публикаций, библиотечной деятельности, издательской деятельности - являются специализацией “минимальной предметной области” описания документов. Примером специализированной схемы является также поддержка специфики описания математической информации. Ещё примеры: поддержка проведения конференций является специализацией общего понятия конференции, поддержка детального описания конкретных типов разработок (программное обеспечение, веб-ресурсы, базы и наборы данных, оборудование) является специализацией общего понятия разработки (“продукта”).
Предметные области совместно с глубиной специализации формируют своего рода иерархическое измерение. Ортогональным к этому измерению является измерение возможных аспектов описания сущностей. Помимо основного “предметного” аспекта, в базовом наборе элементов метаданных ЕНИП выделяются следующие аспекты:
Каждая сущность может характеризоваться собственным набором свойств, соответствующих конкретному аспекту, но, тем не менее, понятие аспекта независимо от типа сущности и, как правило, присуще всем типам сущностей, независимо от предметной области.
Подробнее механизмы организации модульных OWL-схем ЕНИП описаны в статье [1].
Основные понятия спецификации схемы в ЕНИП
Для понимания предложений по элементам научных метаданных ЕНИП существенно также вкратце пояснить основные понятия языка OWL, а также специфические понятия схем ЕНИП.
При описании схемы (онтологии) на OWL может определяться набор классов, набор свойств, а также может быть указан ряд утверждений об этих классах и свойствах, либо о классах и свойствах, определенных другими онтологиями. Следует отметить, что классы и свойства рассматриваются ортогонально: свойство определяется не в контексте класса, а независимо, и может быть использовано в различных классах.
Традиционно, одни классы могут быть подклассами других (например, “агент” – “персона”, “деятельность” – “проект”), в частности, допускается множественное наследование. Помимо этого, и для свойств есть понятие подсвойств. Подсвойство уточняет и специализирует смысл по сравнению с суперсвойством (например, свойство “участник” – подсвойства “руководитель”, “ответственное лицо”; свойство “название” – подсвойства “сокращенное название”, “официальное наименование”). На свойства могут быть указаны глобальные ограничения: его тип значений (примитивный тип XML Schema, либо объектный класс), область применения (класс, к которому относится это свойство, если указан), а также глобальные характеристики: обратное свойство, функциональность и пр. Помимо этого, в OWL возможно указание локальных ограничений на свойство в контексте некоторого класса: уточнение типа значений, мощности свойства (обязательность, допустимое количество значений) и пр.
Существенным для описания схем ЕНИП является также понятие контролируемых словарей – аналогов перечислимых типов XML Schema. Однако, в отличие от значений перечислимого типа, элементы контролируемого словаря являются полноценными ресурсами, имеющими собственные характеристики (такие как название, описание, а возможно и собственные поля), контролируемый словарь может быть расширяем, и пр. Кроме того, контролируемый словарь может быть организован иерархически, в таком случае он называется классификатором (рубрикатором), а также может быть организован в структуру тезауруса.
Основной профиль метаданных ЕНИП
Ниже приводится обзорное описание основного профиля схем метаданных ЕНИП. Детальное описание основного профиля, а также описание остальных схем и предложений ЕНИП, пояснение способа формирования RDF/XML-документов для обмена данными в соответствие со схемами ЕНИП и пр. - приведено в издаваемом Руководстве по схемам метаданных ЕНИП.
Предлагаемое обзорное описание структурировано следующим образом. В виде структурированного списка приводится определение основных классов, для каждого из которых приводится состав свойств данного класса и состав подклассов; аналогично описываются и подклассы. Следует учитывать, что каждый из подклассов наследует состав свойств, определенный в суперклассе. Также, для свойств, значением которых является подструктура, приведено описание состава полей подструктуры.
Описания классов и состава свойств разбиты на отдельные ЕНИП-схемы (указаны курсивом), в которых определяются данные классы или свойства, согласно описанной стратегии организации элементов метаданных ЕНИП. Так, схема описания действующего лица вводит понятие класса “Лицо” (субъект деятельности) и определяет ряд свойств этого класса. Минимальная подсхема описания организаций вводит понятие его подкласса “Организация”, минимальная подсхема описания персон вводит понятие подкласса “Персона”, далее базовые и расширенные схемы, а также схемы академического и исторического аспектов описания персон и организаций вводят дополнительные свойства к этим классам, и так далее.
Итак, основной профиль метаданных ЕНИП включает следующие схемы, классы и свойства:
Минимальная схема описания действующего лица:
Класс Лицо - Субъект деятельности (т.н. “агент”), то есть действующее лицо проектов и мероприятий, автор или участник разработок и публикаций. К этому классу относятся персоны, группы и коллективы, организационные единицы. Свойства класса:
Базовая схема организаций:
Расширенная схема организаций:
Академическая схема организации:
Историческая схема организационных единиц:
Расширенная схема организаций:
Свойства класса:
Схема описания структуры организации:
Академическая схема организации:
Схема описания структуры организации:
Свойства класса:
Схема штата организаций:
Общая схема должности:
Историческая схема должностей:
Схема штата организаций:
Поддержка контролируемого словаря штатных должностей:
Базовая схема описания персоны:
Расширенная схема описания персоны:
Расширенная схема описания персоны:
Академическая схема описания персоны:
Историческая схема описания персоны:
Схема штата организаций:
Минимальная схема деятельности:
Класс Деятельность - Общий суперкласс для деятельности (проекты, мероприятия и т.д.). Деятельность имеет даты начала и окончания, исполнителей и описательные характеристики. Общий суперкласс для деятельности (проекты конференции и т.д.). Деятельность имеет даты начала и окончания. Свойства класса:
Базовая схема проектов:
Расширенное описание проектов:
Академическая схема проектов:
Схема мероприятий:
Свойства класса:
Минимальная схема результатов деятельности:
Класс Результат деятельности - Данный класс описывает разработки (“продукты”), документы и прочие результаты деятельности.
Свойства класса:
Схема документов:
Литература