СИСТЕМА ВИРТУАЛЬНОЙ ИНТЕГРАЦИИ
БИБЛИОГРАФИЧЕСКИХ
ДАННЫХ
А.М. Сенько, М.М. Якшин
(БЕН
РАН)
В настоящее время в мире накоплены значительные объемы информации. Все большее число людей при поиске информации обращаются к сети Интернет. При этом им приходится работать со множеством разнообразных коллекций и баз данных, предоставляемых различными организациями. Эти коллекции сильно различаются между собой по структуре, тематической направленности, полноте представляемых данных. Таким образом, желание пользователя работать с сетью Интернет как с единым источником информации не находит отражения в текущем положении дел. Многочисленные каталоги и поисковые машины также не решают эту проблему.
Многие организации сталкиваются с необходимостью предоставления доступа к своим информационным ресурсам в режиме онлайн. Часто для решения этой задачи разрабатывается специальная система, ориентированная на работу с конкретным информационным массивом. Примерами такого подхода являются, в частности, многочисленные системы работы с библиографической информацией. Такие системы обычно предоставляют пользователям специализированные интерфейсы доступа к данным, позволяющие получать детальную информацию, содержащуюся в поддерживаемой базе данных. В то же время, при работе с такими системами пользователь может столкнуться с рядом проблем, затрудняющих поиск информации. Эти проблемы могут быть вызваны различными причинами, в том числе:
В применении к библиографическим системам можно сказать, что это создает трудности для большинства научных работников и студентов, плотно работающих с литературой.
Сказанное выше обусловливает целесообразность разработки комплекса программ и форматов, позволяющих работать с базами данных информационных ресурсов, различными по структуре и содержанию, используя при этом универсальный интерфейс доступа.
В настоящее время получили распространение три основных подхода к интеграции разнородных коллекций:
Последний подход возник относительно недавно и был выбран в качестве основного при создании описываемой системы виртуальной интеграции библиографических данных.
Существует уже множество реализаций подобных систем. Получившей наибольшее распространение основой для них можно считать протокол Z39.50, пользующийся достаточной популярностью. Z39.50 - достаточно старый стандарт, и в целом он оправданно поддерживается во множестве библиографических систем по всему миру. Но, несмотря на все свои достоинства, у него есть существенные недостатки, к которым можно отнести, в первую очередь, его чрезмерную ориентированность на MARC-форматы, которые также устарели и медленно замещаются теперь форматами, базирующимися на XML. Хотя Z39.50 имеет средства передачи XML, он никак не использует преимущества таких форматов, фактически передавая XML, точно так же, как и любую другую информацию - без разбора в бинарном виде.
Но современные технологии не стоят на месте и появляются все новые подходы для организации транспортного уровня для систем подобного класса. В качестве одного из таких решений выступает протокол XMPP/Jabber - не так давно разработанный на базе системы мгновенного обмена сообщениями (сходной с популярной ICQ), а сейчас эволюционировавший в полноценный транспортный протокол XML-роутинга.
Описываемая система является рабочим прототипом системы, показывающей основные возможности и преимущества решений на основе Jabber. Так как схема клиент-серверного взаимодействия на этой платформе разработана уже довольно давно, и существуют значительные объемы соответствующих программных средств и развитая система полезных дополнений (в частности, система JEP'ов - Jabber Enhancement Proposals - предложений о расширении Jabber), платформа обеспечена готовыми решениями, например, для обеспечения безопасности соединений посредством механизмов SSL и PGP, межсерверного обмена, распределения и балансировки нагрузки и многими другими современными атрибутами.
В задачу настоящего проекта входило создание действующего минимального прототипа системы, предоставляющего универсальный интерфейс доступа к гетерогенным библиографическим базам данных. На этом этапе не рассматривались проблемы объединения результатов распределенного поиска, полученных от нескольких баз данных, их ранжирования и т.п.
Основными задачами проекта являлись следующие:
Основой системы виртуальной интеграции является единый формат передачи данных (и, соответственно, единая схема данных). Разработанная система ориентирована на работу с информационными ресурсами, в частности, с библиографическими данными. В связи с этим к формату предъявляются следующие требования:
Так как система носит экспериментальный характер и в ней сделана попытка воплотить совокупность сразу нескольких идей (в частности, на идеологии схемы данных базируется пользовательский интерфейс поиска), было принято решение основывать формат на чистом XML (без использования популярных сейчас расширений RDF, которые бы излишне усложнили обычную древовидную структуру). Для использования в системе был разработан формат, получивший рабочее название BibXML. В основе этого формата лежит идея о том, что каждый ресурс может содержать описания связанных с ним объектов (персон, организаций, других ресурсов), а также набор простых атрибутов (заглавия, даты и пр.).
Формат разрабатывался, базируясь на трех основных первоисточниках: библиографических ГОСТах, описании форматов типа MARC и рекомендациях IFLA. Формат ориентирован на сущности. Каждая сущность ("ресурс", "человек" или "организация") обозначается одним XML-элементом. Так как формат ориентирован на представление библиографической и связанной с ней информации, на верхних уровнях введены сущности, возвращаемые в запросе, такие как "ресурс-статья", "ресурс-книга", "ресурс-сериальное издание" и т. п. Внутрь каждой сущности вкладываются все сущности, имеющие отношение к ним. Так, например, в сущность "ресурс" на верхнем уровне могут вкладываться описания автора ("человек"), издательства ("организация"). В более сложных случаях в ресурс могут вкладываться другие ресурсы (например, в ресурс типа "многотомное издание" могут быть вложены ресурсы типа "отдельные тома").
Одна и та же сущность, например, "человек", всегда задается одним и тем же элементом (в данном случае - "person"). Если сущность исполняет некую роль в данном контексте, например, человек является автором, то это отражается XML-атрибутами, например - type="author". Атрибут type предоставляет формализованную возможность задания роли сущности, т.е. в DTD формата прописаны все возможные константы-значения атрибута type. В случае, если необходимо определить какую-то разновидность роли, сложно формализуемую, можно использовать атрибут role, который позволяет задавать неформализованные описания в виде обычного текста.
Пример библиографического описания в формате BibXML приведен ниже. Этот пример описания взят из приложений к ГОСТ 7.1-84:
<?xml version = '1.0'?>
<!DOCTYPE resource SYSTEM "bibxml.dtd">
<resource type="book">
<person type="author">
<name type="first">Владимир</name>
<name type="father">Ильич</name>
<name type="last">Ленин</name>
</person>
<title type="main">Задачи союзов молодежи: (Речь на III Всерос. съезде Рос. Ком. Союза Молодежи 2 окт. 1920 г.)</title>
<place type="publication">М.</place>
<organization type="publisher">
<name>Политиздат</name>
</organization>
<date type="publication">
<year>1982</year>
</date>
<pages units="pages">169</pages>
<pages units="sheets" role="ил.">1</pages>
<size type="height" units="cm">17</size>
<comment>Текст на одной стороне л.</comment>
<price units="roubles">0.35</price>
<quantity>10000</quantity>
</resource>
Предложенный формат выполняет двоякую роль: он используется для составления в его терминах запросов (универсализация языка запросов и использование некоторых правил обработки запросов - см. ниже) и для возвращения результатов. Как будет показано ниже, четкая древовидность формата используется для создания оригинального интерфейса клиента.
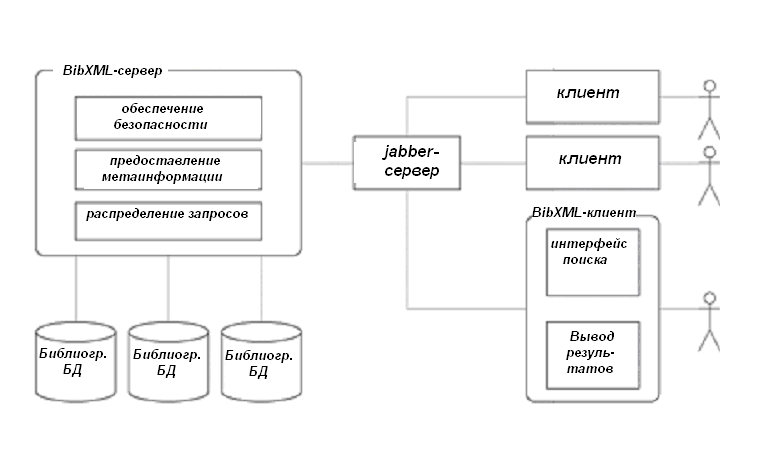
Рассмотрим общую структуру системы, представленную на рис. 1.
Рис.1
Основой системы, как и любой системы, основанной на XMPP/Jabber, является связка Jabber-сервера и Jabber-клиента. Все сущности, обменивающиеся XML-пакетами в XMPP/Jabber, имеют свой уникальный идентификатор, т.н. Jabber ID или JID, который обычно выглядит как адрес e-mail: user@host. Jabber-сервер используется любой стандартный, поддерживающий механизм подключения к нему дополнительных модулей через механизм connect/accept. В данном случае, такой подключаемый модуль, т.н. "транспорт", предоставляет пространство виртуальных JID'ов, по одному на каждую поддерживаемую базу данных. Запрос от пользователя в данном случае отправляется с JID'а пользователя вида user@host на JID базы данных вида db@transport.host, поддерживаемой транспортом. В случае необходимости посылки запроса сразу нескольким базам данных, JID'ы могут объединены в группы, которым можно посылать запрос.
Cерверная часть системы виртуальной интеграции (транспорт) состоит из ядра и модулей для каждой обслуживаемой базы данных.
Ядро выполняет следующие функции:
Модули баз данных содержат конвертеры внутреннего представления библиографических данных в формат BibXML и обратно, а также средства работы с БД.
Поскольку сервер BibXML не имеет никакой информации относительно структуры базы данных библиографических описаний, с которой он взаимодействует, необходимо использовать промежуточный слой, т. е. модуль, отвечающий за преобразование запроса в формате BibXML в запрос, специфичный для обслуживаемой им базы данных, его выполнение и выдачу результатов в формате BibXML. Таким образом, данный модуль выполняет инкапсуляцию обслуживаемой базы данных, позволяя серверу обращаться к любой базе данных, используя универсальный интерфейс, предоставляемый форматом BibXML.
В принципе, к серверу можно обращаться и с помощью обычного, неспециализированного клиента Jabber, но это крайне неудобно, так как приходящие сообщения-ответы и отправляемые сообщения-запросы придется составлять вручную на XML. Основная задача рядового пользователя - поиск информации, поэтому для него намного лучше использовать специализированный клиент.
Для решения этой задачи был проведен анализ используемых для поиска интерфейсов пользователя, причем основными двумя критериями были простота использования при сохранении возможности создания достаточно сложных, детализированных запросов.
Можно выделить три типа наиболее распространенных пользовательских интерфейсов для поиска:
Для описываемой системы был разработан клиент, предоставляющий универсальный интерфейс для составления поисковых запросов, базирующийся на логике формата BibXML и способный представлять принимаемые ответы на запросы в виде стандартных библиографических описаний по ГОСТ 7.1-84. Пользовательский интерфейс выглядит следующим образом: в окне строится дерево всех сущностей, имеющих соответствующие элементы XML в формате, причем, так как фактически дерево бесконечно рекурсивное, строится оно динамически по запросам пользователя. Каждому узлу дерева пользователь может поставить в соответствие строку поиска, причем при поиске действуют следующие правила:
Такой интерфейс поиска, построенный на базе созданного XML-формата, позволяет решить основные задачи, поставленные выше перед поисковой системой - обеспечение простоты формулировки запросов для конечного пользователя и возможности выполнения достаточно сложных запросов.
После посылки запроса перед клиентом стоит вторая задача - прием ответов и интерпретация их в стандартном виде в соответствии с ГОСТ 7.1-84.
Так как клиент получает от сервера записи в XML-формате, эта задача достаточно элегантно решается с помощью XSLT - стилей трансформаций XML-документов. Было разработано несколько шаблонов для преобразования XML-формата в библиографическое описание. Базовый шаблон - ресурс - вызывает по очереди шаблоны, которые собирают все необходимые области библиографического описания. Полученный в результате трансформации документ является HTML-представлением стандартного описания, которое и выводится пользователю как результат поиска.
Описанные подходы были реализованы в виде системы, обеспечивающей поиск и передачу библиографической информации. Эта система может рассматриваться в качестве прототипа для исследования возможностей создания более сложных систем с использованием вышеназванных технологий. Как показала практика, использование в качестве транспортного уровня XMPP/Jabber значительно упрощает построение подобных систем и предоставляет достаточно много дополнительных возможностей по сравнению с другими известными подходами. В частности, разработанная концепция системы позволяет в дальнейшем легко наращивать функциональность, добавляя для пользователей возможности не только поиска, но и заказа изданий, получения их полных текстов и т.п. Для библиотекарей может быть реализована возможность удаленного редактирования и администрирования баз данных. При реализации распределенного поиска могут быть проще решены задачи объединения различных ответов от серверов и ранжирования данных за счет готового транспортного уровня, основанного на XML. В текущей реализации системы доступны Jabber-транспорт (BibXML-сервер) и отдельный специализированный Jabber-клиент. В перспективе возможно создание большего разнообразия клиентов на различных платформах (при этом существенно упрощается процесс создания клиентов для минимальных встроенных платформ - карманных ПК, мобильных телефонов и т.п.) и расширение функциональных возможностей системы.