JAVA И XML ТЕХНОЛОГИИ
НОВОЙ ВЕРСИИ ИСИР
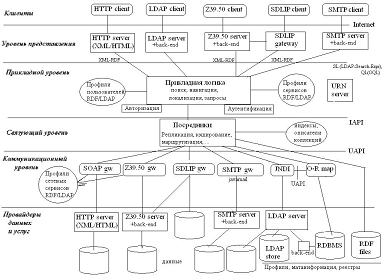
Абстрактная архитектура
Новая версия ИСИР ориентируется на реализацию ключевых средств корпоративных порталов. Корпоративный портал выступает в роли посредника, направляющего обращения пользователей к совокупности сервисов, релевантных данной тематический области, используя открытые прикладные протоколы, такие как HTTP, SOAP, Z39. 50, SDLIP, SDARTS, LDAP и д.р. Среди основных задач портала обеспечение операций обнаружения ресурса, локализации его местоположения, запроса и доставки ресурса.
Реализация исходит из общей многоуровневой архитектуры [MIA]. Цель выделения уровней, которые в свою очередь содержат компоненты и модули, состоит в том, чтобы обеспечить локальное упрощение при поддержке сложных функциональных возможностей. Каждый уровень имеет собственные цели и абстракции, взаимодействие между уровнями ограничено. Модульная организация обеспечивает возможности простого расширения функциональных возможностей системы, простую интеграцию новых высокоуровневых сервисов с существующими. Общая архитектура определяет согласованные интерфейсы между уровнями, интерфейсы для поддерживаемой совокупности протоколов, используемых как клиентами системы (например, HTTP, SOAP, Z39.50, LDAP), так и провайдерами данных и услуг (например, HTTP, OAIP, SOAP, Z39.50, SDLIP, LDAP, SDARTS, FTP), интерфейсы для базового множества операций таких, как поиск, локализация, запрос, доставка. Общая архитектура выделяет следующие уровни. (Рис. 1)
Рис. 1.
Уровень представления. Этот уровень отвечает за представление информации пользователям и обеспечение пользовательского ввода. Он должен поддерживать как web-интерфейсы, так и не web-интерфейсы. Должен уметь генерировать представление на HTML, XML языках, и другие представления, если такие потребуются специальным приложениям. Информация, вводимая пользователем, передается вниз на прикладной уровень, что может осуществляться посредством создания программных объектов для передачи их через согласованные API/интерфейсы или с помощью кодирования данных в специфическом транспортном формате (сериализации), например XML.
Прикладной уровень. Прикладной уровень обеспечивает реализацию прикладных операций, необходимых пользователям или программным агентам в рамках системы. Он отвечает за поддержку логики приложений системы. Прикладные операции - это высокоуровневые сервисы, реализуемые на основе низкоуровневых функций связующего программного обеспечения (промежуточного уровня). Прикладной уровень может поставлять на уровень представления и собственные сервисы, не зависящие от нижних уровней, например, сервис персонификации. Уровень отвечает за поддержку пользовательских профилей, за ведение сессий пользователей. Может приспосабливать информационное окружение под определенные сообщества пользователей. Например, может предоставлять предварительно сформированные поисковые запросы, средства типа закладок или рекомендаций. В его задачу входит адаптация запросов и их результатов к текущей ситуации, определяемой событиями сессии и профилем пользователя. Например, при поступлении поискового запроса в него могут включаться ограничения, определенные в профиле и обуславливаемые известными рубрикаторами. Аналогичное согласование данных может происходить при возврате результатов, например, из результата могут удаляться ресурсы, предоставленные пользователю ранее в ходе текущего сеанса.
Связующий уровень. Этот уровень (уровень промежуточного связующего программного обеспечения - посредника) ответственен за понимание значения сервисов, запрашиваемых прикладным уровнем, и сервисов, предоставляемых провайдерами. Связующий уровень, получая запросы от прикладного уровня, должен определить, какие из провайдеров услуг могут удовлетворить запрос, возможно, сложная комбинация из них, например, найти описание книги и указать все библиотеки, имеющие эту книгу, или интерактивные книжные магазины, имеющие её в продаже. Связующий уровень может обеспечивать управление авторскими правами.
Коммуникационный уровень. Коммуникационный уровень обеспечивает единообразное представление провайдеров данных, использующих разные сетевые возможности. Он ответственен за коммуникации с внешними сервисами, скрывает от связующего уровня такие подробности, как коммуникационные протоколы, расположение внешних сервисов. Он может обеспечивать отображение между словарями метаданных, чтобы поддержать термины, понятные связующему уровню. В некоторых случаях сервисы провайдеров (внешних сервисов) могут "непосредственно" взаимодействовать со связующим уровнем, в таких случаях действие, выполняемое коммуникационным уровнем, тривиально. Коммуникационный уровень обеспечивает связь между связующим уровнем и провайдерами, основываясь на профиле сетевого сервиса, связанным с каждым сервисом, предоставляемым поставщиками. Профиль сетевого сервиса предоставляет информацию о расположении, протоколе, языке запросов и форматах ответов и словарях метаданных, требуемых для осмысленного доступа к внешнему сервису.
Уровень провайдеров данных и услуг. Уровень провайдеров данных и услуг включает все внешние сервисы, предоставляемые провайдерами в соответствии с профилями сетевых сервисов. Уровень включает "первичные" сервисы, на основе которых функционирует система, которые обеспечиваю доступ, например, к библиотечным каталогам, сервисам реферирования и тематическим шлюзам. Он также включает "вторичные" сервисы, используемые системой при предоставлении "первичных" сервисов. Это, например, могут быть реестры схем метаданных, сервисы аутентификации, пользовательские профили.
Ключевую роль в этой архитектуре играют репозиторный сервис и механизмы глобальной идентификации и контроля доступа. Основываясь на услугах репозиторного сервиса, сервисы следующих уровней - репликационный, индексный, поисковый, метаинформации, составляющие совместно с базовыми стек сервисов сервера, обеспечивают обмен данными и поиск в распределенной среде.
Службы поддержки репозиториев
Технологии ИСИР ориентируются на формирование единой корпоративной информационной системы из разнородных хранилищ и источников информации в распределенной среде, включая объектные и реляционные базы данных, LDAP-каталоги и пр. Каждое полнофункциональное хранилище называется репозиторием. ИСИР предоставляет многочисленные службы по поддержке репозиториев, например репликацию и обмен данными, индексирование и поиск, технологию построения web-порталов для доступа к данным.
Основой новой версии ИСИР является объектно-ориентированный подход к представлению данных. Использование такого подхода унифицирует модель хранимых данных, облегчает процесс интеграции с Semantic Web, XML-технологиями, стандартами OMG и ODMG. Использование понятия "хранимых объектов" в объектно-ориентированном языке программирования (на платформах Java, .NET) позволяет разработчикам прикладных приложений на базе ИСИР-технологий абстрагироваться от ненужных деталей и сконцентрировать своё внимание собственно на логике приложения. В результате - меньше ошибок, красивее, понятнее и короче код.
Каждый репозиторий не универсален: он не может, и не должен хранить "что угодно". Репозиторий специализируется в своей предметной области и способен хранить данные, соответствующие своей объектной схеме, которая описывает используемые классы и свойства. Ядро ИСИР обеспечивает механизм отображения объектной модели данных во внутреннюю модель данных используемого хранилища (реляционную, LDAP...). Так, в реляционной базе данных объектной схеме соответствует структура таблиц. С помощью такого механизма отображения ядро фактически превращает низлежащее хранилище в объектную базу данных и позволяет прикладному коду работать с "хранимыми объектами", изменения в которых прозрачно отображаются в хранилище. На данном этапе подобный механизм отображения поддерживается для всех распространённых реляционных СУБД, разрабатывается отображение в LDAP. Кроме того, Sun Microsystems предлагает стандартную архитектуру Java Data Objects для прозрачного хранения Java-объектов в различных базах данных и иных системах. Любая сторонняя реализация этой спецификации может быть подключена в Ядро ИСИР.
Как фундамент для описания объектных схем ИСИР использует язык RDF Schema - за простую объектную модель, удобство расширения новыми примитивами, адаптацию к Web и преимущества, приносимые при обмене RDF/XML данными. Модель данных RDFS представляет собой выражение ER и объектной модели данных в распределённой среде Web. Причиной отличия модели RDFS от традиционной объектной парадигмы является децентрализализация и глобализация информационной системы, к которой мы приходим, выходя из установленных моделью данных рамок в Web. ИСИР расширяет RDFS необходимыми примитивами, которые позволяют эффективно использовать этот язык для отражения как глобального, так и локального аспектов информационной системы. Каждый репозиторий рассматривает свою RDF-схему как замкнутое жёсткое описание собственной объектной схемы данных, которой соответствует структура "хранимых" java-классов и схема хранилища, например реляционной БД. С другой стороны, использование RDFS и технологий Semantic Web приносит существенные выгоды при интеграции различных репозиториев в единую информационную среду, взаимодействии со сторонними информационными источниками.
Приоритетное положение RDFS в ИСИР не мешает изначально описать объектную схему репозитория на ODL [ODMG], смоделировать на UML [UML], либо получить по существующей системе Java-классов. ИСИР предоставляет некоторые механизмы по отображению таких описаний друг в друга и их генерации.
Генератор Java-классов позволяет получить по ИСИР RDFS-описанию исходный код bean-подобных "хранимых классов". В эти классы вручную может быть заложена любая бизнес-логика, заменяющая или дополняющая исходное поведение. При изменении схемы (например, добавлении свойств) будет произведена инкрементная перегенерация классов - внесённые в код изменения будут сохранены. Таким образом, не ограничивая функциональных возможностей системы, RDFS позволяет автоматизировать большинство операций. Ядро и сервисы ИСИР параметризуются объектной схемой, и способны работать с любой нужной предметной областью.
Генератор реляционной БД позволяет получить по ИСИР RDFS-описанию SQL DDL-скрипт для создания таблиц, в которых будут храниться данные, и описание объектно-реляционного отображения. Процесс генерации является настраиваемым, и дизайнер может явно указать, какие примитивы реляционной БД необходимо использовать для заданных примитивов объектной схемы в том или ином случае, например, какое решение применить для поддержки наследования классов. Настройки генератора указываются в RDF-формате вместе с объектной схемой, благодаря расширяемости RDFS. В случае, когда необходимо настроить ИСИР-систему на имеющееся унаследованное хранилище, необходимо вручную описать аналогичное отображение. Например, для настройки на имеющуюся реляционную БД, необходимо с помощью графического интерфейса сопоставить таблицы и поля реляционной базы данных классам и свойствам объектной схемы. Благодаря настраиваемому отображению объектов в модель данных хранилища, ИСИР позволяет вывести унаследованные базы данных на новый уровень, открывая к ним доступ ведущим Web-технологиям и Semantic Web.
Сервисы ядра
Вся функциональность ядра обеспечивается специальными компонентами, называемые сервисами. Каждый сервис отвечает конкретным функциональным потребностям - хранение объектов, наблюдение за хранимыми объектами, аутентификация пользователей, авторизация доступа и пр. Сервисы ядра используют функциональные возможности друг друга. Реализация сервисов - заменяемая, такая организация обеспечивает модульность программной среды.
Как уже упоминалось, ИСИР-приложения, фактически, работают с объектной базой данных, надстроенной над реальным хранилищем. Доступ к такой объектной БД предоставляется репозиторным сервисом ядра (Persistence Service). Интерфейс этого сервиса является подмножеством стандартного интерфейса объектных баз данных ODMG, который позволяет извлекать нужные объекты SQL-запросами, управлять транзакциями. Приложение работает с полученными из репозиторного сервиса "управляемыми" объектами как с обычными объектами языка Java - вызывает их методы, меняет свойства - и при успешном завершении транзакции изменения отражаются в хранилище.
"Сервис глобального наблюдения" ядра предоставляет возможность регистрировать в системе "наблюдателей", получающих уведомления об изменении состояния интересующих их хранимых объектов. Эти наблюдатели могут делать необходимые проверки (например, проверки прав доступа), изменять связанную с данным объектом информацию (например, аудит) и пр. Использование "наблюдателей" позволяет придать нужным типам хранимых объектов нужную функциональность, не вкладывая её непосредственно в код класса.
Ядро предоставляет различные встроенные услуги по управлению хранимыми объектами, такие как автоматическая проверка прав доступа, аудит и пр. Для того, чтобы к хранимому классу была подключена некоторая услуга, он должен реализовывать соответствующий маркер-интерфейс. К одному классу могут быть подключены несколько услуг одновременно (например "зависимый объект" и персональные права доступа). В ИСИР RDFS подключению услуг соответствует наследование классов от предопределённых ядерных "абстрактных классов". В ядро ИСИР включены следующие типы объектов:
В дополнение к обеспечению отображения объектов в хранилище, репозиторный сервис предоставляет возможность работать с хранилищем напрямую через специальные подкомпоненты - plugins. Они позволяют выполнять операции, которые были бы неэффективными, если бы для этого использовались хранимые объекты и ODMG API. Например, бессмысленно реализовывать систему проверки прав доступа с помощью хранимых объектов и OQL-запросов, когда реальным хранилищем является реляционная БД, гораздо более подходящая для таких целей. Система безопасности ядра использует для этих целей специальный plugin. Другой пример - поддержка иерархических запросов, выбирающих, например, предков или потомков по дереву или направленному ацикличному графу (DAG). OQL не приспособлен для подобных нужд, в то время как реляционные БД позволяют эффективно выполнять подобные запросы. Система категоризации ядра использует подобный plugin для поддержания иерархических структур различных хранимых объектов (подчинение организаций, система директорий...) и оптимизации запросов.
Сервис аутентификации отвечает за вход пользователей в систему. Многие компоненты ядра, например система безопасности, аудита и пр., используют этот сервис для выяснения текущего пользователя.
Сервис авторизации (Permission Service) отвечает за проверку прав доступа к объектам типа SecureObject и управление их правами доступа. Права доступа выражаются в виде списка разрешений
- Access Control List. Каждый элемент списка - это тройка <лицо, объект, привилегия>, где лицо это пользователь или группа, объект это SecureObject-объект, к которому относится разрешение, а привилегия выражает некоторую операцию, которую пользователь может производить над объектом. Вот список привелегий, используемых ядром:
Разрешения, непосредственно указанные в списке, называются прямыми разрешениями. Кроме этих разрешений существуют неявные разрешения, вычисляющиеся по следующим правилам:
Отсутствие прямого или неявного разрешения на некоторую операцию означает отсутствие данной привилегии данному пользователю над данным объектом, то есть запрет операции.
Система безопасности ядра рассчитана на среду с большим количеством защищенных объектов и пользователей. Крупные информационные объекты, потенциально нуждающиеся в персональных правах доступа, относят к SecureObject. Эти объекты могут наследовать права доступа согласно административной или другой структуре. Например, права доступа к подразделению могут быть унаследованы от организации, содержащей это подразделение. Права доступа к штатному сотруднику подразделения - определяться правами доступа к подразделению.
Крупные группирующие объекты (организации, подразделения) относят к группам, подчинению организаций сопоставляют вложенность групп. Штатные сотрудники считаются пользователями системы и привязываются к этим группам. Далее, достаточно дать одной организации (как группе) право на чтение другой, и все её сотрудники (как пользователи) получат права на чтение всех ресурсов этой организации - подразделений, штатной информации...
Использование объектов типа DependentObject позволяет облегчить процесс проверки прав доступа, если объект не нуждается в персональных правах. Так, доступ к элементам штата (должностям) организации всецело определяется доступом к организации. Бессмысленно делать должность SecureObject и явно задавать наследование прав доступа от организации для каждой должности. Вместо этого достаточно сделать должность зависимым от организации объектом. Для чтения, модификации зависимого объекта необходимо иметь право на чтение, модификацию объекта-контекста. Таким образом, должности попадают под политику безопасности для организации. Ещё более очевидный пример - имя персоны, вынесенное в отдельный объект. Всё, что нужно сделать - это указать, что имя персоны является объектом, зависимым от персоны.
Возможны и более сложные комбинации из зависимых и безопасных объектов. Объект может одновременно являться DependentObject и SecureObject, то есть иметь персональные права доступа. Тогда для его чтения, модификации, удаления необходимо не только личное разрешение для этого объекта, но и аналогичное разрешение для его объекта-контекста. Например, полный текст публикации может выставляться за отдельную плату, в то время как информация о публикации (название, авторы и пр.) - быть публично доступной.
Сервис авторизации используется системой безопасности внутри ядра, но может быть использован и прикладным кодом. Приложение может определить новые привелегии (например, право на некоторую сложную операцию по изменению объекта), неизвестные ядру, и проверять их самостоятельно (например, в теле метода, производящего эту операцию).
Ядро обеспечивает поддержку аудита изменений для всех AuditedObject-объектов - это делается с помощью специального наблюдателя, зарегистрированного в "сервисе глобального наблюдения". Сервис аудита позволяет получить эту информацию.
Высокоуровневые сервисы
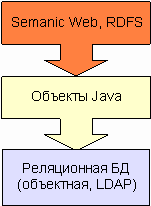 Таким образом, ядро позволяет абстрагироваться от
конкретного устройства хранилища и работать с хранимыми Java-объектами,
соответствующими объектной схеме репозитория. Многие службы, тем не менее,
нуждаются в более общей абстракции - они не должны зависеть от конкретной
объектной схемы, а должны быть способны работать с разными репозиториями и
схемами. Такие службы работают не напрямую с Persistence Service ядра и
хранимыми Java-объектами, а с абстрактным программным интерфейсом Unified
API.
Таким образом, ядро позволяет абстрагироваться от
конкретного устройства хранилища и работать с хранимыми Java-объектами,
соответствующими объектной схеме репозитория. Многие службы, тем не менее,
нуждаются в более общей абстракции - они не должны зависеть от конкретной
объектной схемы, а должны быть способны работать с разными репозиториями и
схемами. Такие службы работают не напрямую с Persistence Service ядра и
хранимыми Java-объектами, а с абстрактным программным интерфейсом Unified
API.
Unified API представляет собой набор простых Java-интерфейсов, ориентированных на работу с RDF-совместимыми данными. Хранимые в репозитории объекты здесь представляется согласно модели данных Semantic Web в виде направленного графа, где вершинами являются объекты, а рёбрами - именованные URI свойства (в соответствие с RDF-схемой репозитория). Схемонезависимый прикладной код использует переданное ему описание RDF-схемы и Unified-интерфейс к репозиторию для работы с хранилищем.
Unified API предельно прост в реализации, что позволяет применить часть архитектуры ИСИР ко внешним источникам информации, над которыми не может быть реализован "тяжелый" репозиторный сервис ядра. Это позволяет организовать обмен данными, репликацию, индексирование и поиск не только для репозиториев, построенных на базе ядра ИСИР, но и для внешних источников, над которыми реализован Unified API.
На базе ядра и Unified API строятся более высокоуровневые службы ИСИР:
XML-технологии в ИСИР
Архитектура ИСИР повсеместно использует XML и сопутствующие технологии. XML-представление данных является такой же неотъемлемой частью ИСИР, как и объектное представление. XML-представление объектных данных позволяет применить к ним всю мощь XML-технологий и интегрировать в архитектуру различные разработки, связанные с XML-технологиями.
Представление объектной информации в виде XML в ИСИР опирается на идеи и механизмы Semantic Web. Этот W3C-проект являет собой логическое продолжение развития web - от гипертекстовых страниц к структурированным XML-документам, а затем к смысловому содержанию и адекватной машинной интерпретации данных. Модель данных Sematic Web представляет собой выражение объектной и ER-моделей данных в глобальном аспекте Web - объекты и их свойства идентифицируются здесь с помощью URI. Semantic Web определяет принципы записи таких данных в XML (RDF/XML-синтаксис), и ИСИР использует эти принципы для сопоставления XML-схемы и XML-представления объектной схеме и объектному представлению данных.
Представление объектной информации в XML в согласии с принципами Semantic Web приносит ряд существенных преимуществ при обмене этой информацией для интеграции данных различных репозиториев. Структура такого (RDF/XML) файла чётко соответствует объектной схеме репозитория ИСИР, объекты которого представлены в данном XML. Таким образом, RDF-файл несёт в себе семантику сериализованных данных, а не только данные. Получатель сможет правильно сопоставить сериализованные данные с собственной системой классов и свойств, и адекватно их обработать. Это как раз то преимущество, которое несёт Semantic Web - семантическая интероперабельность.
ИСИР интегрирует XML-технологии с Semantic Web, что позволяет эффективно использовать XML (RDF/XML) для обмена информацией как между репозиториями ИСИР, так и со сторонними системами. ИСИР-репозитории могут служить источниками RDF-знаний для сторонних программных агентов Semantic Web, таких как поисковые системы. ИСИР-технологии способны сделать доступным в Semantic Web огромное количество информации, накопленной в не-web базах данных и библиотеках. С другой стороны, Semantic Web помогает ИСИР "добывать" информацию из сторонних источников - доступных в web тезаурусов и классификаторов, баз знаний и пр. систем, с которыми может быть связана информация.
Итак, ИСИР использует XML для представления хранимых данных, когда необходимо воспользоваться услугами технологий, базирующихся на XML (XSLT и XForms, RDF/XML для обмена данными, SOAP..). В многоуровневой архитектуре ИСИР XML-представление данных стоит на следующей ступеньке после Semantic Web и объектного представления, которое в свою очередь стоит над представлением данных в соответствие с типом конкретного хранилища (ODBMS, RDBMS, LDAP..). Уровень Semantic Web представлен интерфейсом Unified API, а с XML-представлением данных имеют дело сервисы сериализации и десериализации.
На базе этих сервисов строится сервис репликации данных между репозиториями, распределенными в web. Служба индексации ИСИР также связана с XML и Semantic Web - она обеспечивает построение поатрибутного полнотекстового индекса по RDF/XML-данным индексируемых объектов. Эта служба может использоваться как для индексации локального репозитория ИСИР, так и для индексации внешних источников Semantic Web, построенных не на ИСИР-технологиях. Это может быть полезно, в частности, для интеграции с унаследованными системами, над которыми сложно поддержать работу ядра ИСИР, либо для легковесной индексации данных без привлечения других ИСИР-технологий, когда они не требуются.
Наконец, ИСИР поддерживает возможности доступа к репозиторию по протоколу SOAP, то есть позволяет организовать Web-сервис на базе репозитория. Среди функций такого web-сервиса - сериализация в RDF/XML хранимых объектов, выбранных поисковым запросом, и модификация хранимых объектов согласно предоставленному клиентом RDF/XML.
Web-публикация и XSLT
Упомянутые выше службы ориентированы в большей степени на обмен или обработку данных, и используют XML для представления этих данных в сериализованной форме. Другой аспект использования XML-технологий в ИСИР - это web-публикация информации с применением XSLT. Использование XML/XSLT для построения ИСИР web-порталов позволяет, во-первых, разделить логику выборки данных и стиль их представления, то есть разграничить области ответственности дизайнера и программиста. В результате дизайн сайта может эволюционировать со временем независимо от его информационного наполнения. Во-вторых, мы получаем возможность представлять страницу пользователю в различных форматах помимо HTML (WML для сотовых телефонов, PDF для печати, Excel для отчётов, SVG для графиков, RDF для метаданных).
Таким образом, для каждой "активной страницы" портала необходимо отдельно описать:
При разработке всех компонентов архитектуры ИСИР мы придерживаемся общей стратегии следования открытым стандартам и общепризнанным решениям. В плане XML-изации web-сервера с применением XML/XSLT-технологий и разделением данных, логики и представления в Java Community отлично зарекомендовал себя Apache-проект Cocoon. Open-source проекты в Java имеют очень приятную тенденцию - перерастать в стандарты Java Community Process и становиться эталонной реализацией стандарта (Reference Implementation). Мы рассчитываем, что это произойдёт и с Cocoon.
Cocoon опирается на простую конвейерную модель обработки: XML-документ проходит через конвейер, который представляет собой несколько фаз преобразования данных. Каждый конвейер начинается генератором (точка средоточения логики и данных), содержит несколько преобразователей (например, XSLT), и завершается сериализатором. По конвейеру происходит постепенное перемещение потока XML-информации, с преобразованием её от исходного XML данных (content) к нужному XML представления. XML-информация предстаёт здесь в виде потока SAX-событий, то есть событий открытия и закрытия XML-элементов.
Простейший сериализатор просто преобразует SAX-поток в поток символов соответствующего XML-файла, либо HTML, WML, SVG, VRML, но возможно и преобразование SVG в JPEG или PNG-формат, либо трансляция XSL Formatting Objects в PDF, PostScript, Excel форматы.
Cocoon обобщает понятие "активных серверных страниц" на случай XML/XSLT-публикации данных, вводя механизм XML-серверных страниц (Extensible Server Pages - XSP). JSP, ASP и пр. являлись конгломератом логики, данных и представления, что недопустимо для крупных приложений. XSP же позволяет сконцентрировать своё внимание на формировании данных страницы, переложив задачу представления на плечи XSLT. XSP-страница прозрачно компилируется в Cocoon Generator и служит начальной точкой конвейера обработки XML-информации в Cocoon. К XML "данным", сформированным XSP-страницей, в конвейере может быть применен ряд трансформаций, после которых на выходе из конвейера мы получаем XML "представления", описывающие, что и как нужно отобразить на экране.
Использовать JSP для написания крупных приложений со сложной логикой обработки было бы очень неудобно, если бы не было механизма библиотек тегов (tag libraries). XSP-страницы также предоставляют возможность преобразовать код в "библиотеки тегов", только в несколько другой форме, чем JSP. Роль "библиотек тегов" здесь играют так называемые logicsheets - логические XSLT-трансформации. Это преобразования, которые применяются к XSP-документу перед его трансляцией в java-код Cocoon генератора. Каждый logicsheet отвечает за преобразование собственных спец-тегов в комбинацию выходного XML-текста, XML-элементов и управляющих конструкций xsp:logic и xsp:expr. Таким образом, logicsheet отвечает за подстановку необходимой логики вместо собственных спец-тегов.
Механизм logicsheet-трансформаций - существенно более гибкий, чем обычный механизм библиотек тегов. Мы получаем полный контроль над обрабатываемым XSP-документом, а не только над тегом, который нужно проинтерпретировать. Это позволяет полностью преобразить логику обработки страницы, использовать "спец-атрибуты" вместо "спец-тегов", необходимым образом проинтерпретировать обычные XML-элементы. Обладая таким инструментом, мы можем сделать страницы ещё проще и удобнее, нежели мы можем себе позволить в JSP.
Этот потенциал XSP позволяет сделать описание логики выборки данных страницы ИСИР-портала максимально декларативным, но при этом расширяемым. XSP-страница, описывающая выборку хранимой в ИСИР-репозитории информации, может содержать сколь угодно сложный java-код, но при этом простые страницы должны быть краткими и понятными непрограммисту (такие страницы сможет разрабатывать и дизайнер, занимающийся XSLT-оформлением). Для этого разработан специальный logicsheet "XML-серверных страниц ИСИР" (ISP*XSP), позволяющий наглядно описать выборку объектных данных из репозитория. Большинство страниц предельно просты - они находят указанный параметром запроса объект и сериализуют в XML нужные атрибуты и связи с другими объектами.
Массив "XML данных", являющийся результатом обработки XML-страниц ИСИР, представляет хранимую объектную информацию в соответствие с принципами Semantic Web и кратким синтаксисом RDF/XML. Структура такого XML-файла чётко соответствует ИСИР RDF-схеме репозитория - это залог семантической интероперабельности распределённых в web приложений. Для иллюстрации, что представляют собой RDF/XML и XML-страницы, приведём небольшой пример (по мотивам бессмертного произведения братьев Стругацких :-)
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="
http://www.w3.org/1999/02/22-rdf-syntax-ns#""XML-серверные страницы ИСИР" соотносятся с подобными RDF/XML-данными точно так же, как JSP соотносятся с HTML. "XML-серверные страницы ИСИР" отвечают за динамическую генерацию RDF/XML-документов, то есть за выборку необходимой объектной информации из хранилища при помощи Ядра ИСИР и представление её в RDF/XML-виде.
Язык "XML-серверных страниц" в ИСИР позволяет максимально наглядно и декларативно описать, какие данные следует выбрать. Такая страница похожа на шаблон XML-документа, в который осталось лишь подставить значения из хранилища. Рассмотрим пример страницы, результатом которой мог бы быть приведённый выше RDF/XML.
<?xml version="1.0"?>
<!--
Смысл такой страницы очевиден - она обращается к Ядру ИСИР и находит в хранилище организацию по числовому id, указанному в параметре HTTP-запроса, а затем выдаёт информацию о её названии, подразделении-дирекции, его должностях и сотрудниках.
Страница очень похожа на шаблон документа - достаточно лишь подставить значения и вы получите приведённый выше XML. Именно этот шаблон занимает основную часть страницы, управляющие теги и атрибуты, выражающие логику работы страницы, не мешают увидеть структуру результирующего документа. Глядя на такой шаблон, web-дизайнер без труда напишет XSLT для форматирования результата этой ISP*XSP, не вдаваясь в логику страницы. Эта страница, как и большинство других, очень проста, но ISP*XSP может использоваться для написания страниц произвольной сложности - такая страница может содержать произвольный управляющий код (циклы, методы, рекурсивные вызовы) - вперемешку с подобными шаблонами.
В завершение следует упомянуть механизмы разработки web-форм, в том числе форм редактирования хранимой информации. Для этих целей могут использоваться две технологии. Для создания форм на JSP разработана специальная среда управления формами (Formbuilder framework), базирующаяся на JSP-библиотеке тегов для генерации HTML-форм и отвечающая за встраивание в формы данных хранимых объектов и обработку результатов редактирования формы. Formbuilder работает напрямую с репозиторным сервисом ядра и хранимыми java-объектами.
Другой механизм создания форм опирается на новую разработку World Wide Web Consortium - спецификацию XForms. Форма в XForms - это XML-данные, которые подлежат редактированию, плюс набор управляющих элементов формы и отображение XML-данных на эти компоненты. Результатом редактирования формы является изменённый XML. Для организации формы редактирования некоторого хранимого объекта нужные свойства этого объекта сериализуются в RDF/XML и подаются в качестве данных формы, а после завершения редактирования результирующий RDF/XML загружается в систему с помощью сервиса десериализации.
Литература