СОВРЕМЕННЫЕ ТЕХНОЛОГИИ В ИНФОРМАЦИОННОМ ОБЕСПЕЧЕНИИ
НАУКИ
СЛУЖБА УПРАВЛЕНИЯ СОДЕРЖАНИЕМ
СИСТЕМЫ ИСИР, ОСНОВАННАЯ НА
XML
ТЕХНОЛОГИЯХ
Т.М. Сысоев (ВЦ РАН), А.А. Бездушный (МФТИ),
А.Н. Бездушный (ВЦ РАН), А.К. Нестеренко (ВЦ
РАН)
Введение
Важная часть любой информационной Web-системы будь то сайт или
портал - это представление информации, данных - содержания системы. В начале
содержание составляли HTML документы, размещенные в файловой структуре.
Управлять такими статическими сайтами могли не очень квалифицированные, но
все-таки программисты. По ряду причин такие решения не могут удовлетворить
потребности как владельцев сайтов, так и их пользователей, поскольку
трудоемкость и стоимость сопровождения велики, невозможно обеспечить поддержку
многих насущных требований - персонификации взаимодействия с пользователями,
поддержку коллективной работы, процессов подготовки информации и т.п. Другое
решение заключается в создании динамических сайтов, генерирующих HTML документы
по запросам пользователей с помощью соответствующих программ на основе данных,
хранящихся в базах данных. Такое решение требует квалифицированных
программистов, следовательно, является существенно более сложным и дорогим в
процессе реализации сайта.
В последнее время все больше внимание уделяется третьему
решению, занимающему промежуточное положение, представляющему собой реализацию
первого решения средствами второго - "динамическое" управление "статическими"
данными. Это так называемые системы управления содержанием/контентом (Content
Management System), представляющие собой динамические сайты или часть оных, в
которых на структуры данных и функциональность накладываются определенные
ограничения. Основными функциями этих систем являются разработка, управление и
каталогизация (классификация) содержания, его визуализация. Этот подход
позволяет получить некоторую "тиражируемую" Web-систему, допускающую ту или иную
степень свободы в изменении стандартных для нее структур данных и
функциональности. Такие Web-системы позволяют существенно снизить трудоемкость
сопровождения и создания ("установки" Web-системы). Часто создание Web-системы
заключается в "аренде" (хостинге) системы управления содержанием у её владельца,
который возлагает на себя ответственность за сопровождение системы, а клиент
остается только сопровождает свои данные.
В результате в Web-системах стали выделять "фасадную"
(front-end) и "тыловую" (back-end) части, отвечающие соответственно за
"статические" и "динамические" данные. К первой категории относят
слабоструктурированную информацию, отличающуюся нерегулярностью взаимосвязей,
достаточно редко модифицируемую, такую как информационно-публицистические
материалы сайта, пресс-релизы, новости. Ко второй категории причисляют
структурированные данные баз данных или xml-хранилищ с регламентированными
взаимосвязями, например, это может быть информация о товарах, организациях,
проектах, реферируемых публикациях и т.п. Граница между этими категориями
достаточно размыта. Любая информация может оказаться как в первой, так и во
второй категории. Все определяется качественными характеристиками информации,
требованиями предметной области прикладной системы, портала.
На сегодня большинство систем, причисляющих себя к системам
управления содержанием, основной своей задачей считают каталогизацию данных
первой категории, причем каждая из них исповедует свои принципы формирования
каталога. Они могут предоставлять широкую гамму возможностей, позволяющих
эффективно взаимодействовать с данными как пользователям, так и разработчикам,
управляющим содержанием сайта.
Часто системы управления содержанием сопровождаются
функциональными модулями, обеспечивающими, например, комментирование,
анкетирование, голосование, ведение дискуссий и обсуждений, то есть
обеспечивающими возможность привязки к разделам и документам данных, отражающих
отношение пользователей к информации сайтов. Важным для CM-систем является
наличие поддержки неких редакционных процессов с разделением ролей авторов и
редакторов, чтобы информация прежде чем быть опубликованной проходила
необходимые стадии обработки, выполняемые разными людьми.
Анализируя рынок систем управления контентом, можно сделать
следующие выводы. В основном CM-системы обеспечивает только иерархическую
каталогизацию данных одного типа - разделы/документы. Как исключение из этого
правила можно упомянуть технологию Communiware (
www.communiware.ru), обеспечивающую
каталогизацию разнотипных связанных объектов, в этом похожую на технологию ИСИР.
Средства управления потоками работ по созданию и управлению содержанием сайта в
CM-системах либо отсутствуют вообще, либо имеются некоторые фиксированные
варианты редакционных процессов. Редко имеются средства атрибутного или
полнотекстового индексирования массивов локальных данных. CMS несовместимы друг
с другом, не поддерживают необходимый уровень экспорта/импорта данных, обмена и
интеграции данных и служб. Большинство разработчиков CMS ведут закрытую
информационную политику в отношении собственных разработок, что осложняет
возможность поддержки интероперабельности систем. Отметим, что в данной работе
мы не представляем всесторонние анализ и обзор имеющихся CM-систем, мы обращаем
ваше внимание на основные характеристики текущего этапа развития CM-систем,
тенденции следующих этапов.
На текущий момент имеются предпосылки для перехода от CM-систем
только с простой каталогизацией неструктурированной информации к CM-системам,
уделяющим существенное внимание структурированию данных, обеспечению
синтаксической и семантической интероперабельности распределенных источников
информации. Задачи реализации средств управления распределенной в Web
информацией последнее время привлекают пристальное внимание разработчиков
информационных технологий. Повышенный интерес к этой проблеме вызван как
сложностью работы с распределенной слабоструктурированной информацией,
находящейся в ведении гетерогенных систем, так и интенсивным развитием новых
Web-технологий в первую очередь XML-технологий.
Данная работа представляет попытку сделать несколько шагов в
этом направлении. В работе представлены технологии визуального представления
данных, удаленного управления ими, атрибутно-полнотекстового индексирования
массивов локальных данных разных форматов. Рассмотрены механизмы поддержки
распределенного поиска и репликации данных - технического фундамента
синтаксической и семантической интероперабельности источников информации.
Проанализирована целесообразность использования ряда существующих открытых
стандартов и технологий. Предложены некоторые дополнения к ним, учитывающие
последние достижения Web-технологий, такие как Web-сервисы и протокол SOAP.
Предложенное решение нашло применение в реализации системы ИСИР
РАН.
Постановка задачи.
В рамках технологии ИСИР существует потребность в реализации
набора служб, обеспечивающих высокоуровневую обработку хранящихся в нём
информационных материалов. На эти службы возлагаются следующие задачи:
- Поддержка визуального представления данных. Решение должно обеспечивать
разделение дизайна и содержания.
- Предоставление заданному кругу лиц возможности управления материалами
портала. Портал должен обладать совокупностью средств, позволяющих
контролируемым образом модифицировать и добавлять данные портала через
Web-интерфейсы.
- Пользователям портала должна предоставляться возможность поиска
информации. При этом необходимо поддерживать различные виды поиска:
полнотекстовый, атрибутный. Результаты поиска должны сортироваться по
релевантности к запросу.
- Поддержка распределённости данных. Это требование порождает качественно
новые задачи, связанные с поддержкой взаимосвязи данных и взаимодействием
сервисов нескольких серверов, для решения которых, в частности, используется
обмен данными и поисковыми индексами по заданной схеме. Обмен данными важен и
с позиции распределения нагрузки и ускорения доступа к информации. Обмен
поисковыми индексами позволяет организовать маршрутизацию поисковых запросов,
повысить эффективность распределённого поиска.
Мы стремимся видеть в CM-системе разностороннюю поддержку
информационного содержания порталов и сайтов. CM-система должна включать службы
управления как неструктурированной, так структурированной информацией, средства
сопряжения слабоструктурированных и структурированных данных, в частности,
включения вторых в первые, механизмы атрибутно-полнотекстового индексирования
данных обоих видов, поддержки синтаксической и семантической интероперабельности
распределенных источников информации. В реализации службы использованы
Java-технологии ряда открытых стандартов, технологий и решений.
Схема зависимости
сервисов.
На схеме показаны сервисы, участвующие в обслуживании данных
порталов на базе технологий ИСИР, стрелками обозначены зависимости между ними.
Например, для обмена индексами используется протокол SOAP, который еще участвует
в реализации распределенного поиска. Серым цветом помечены вспомогательные
сервисы, представляемые другими работами. В данной работе они практически не
рассматриваются.
Управление
слабоструктурированным содержанием сайта.
С точки зрения посетителя сайт представляется в виде набора
страниц, связанных между собой ссылками. Изначально сайты представляли собой
коллекцию HTML документов, размещённую в файловой системе. Обычно страницы
одного сайта имеют похожую структуру и общий дизайн. Это приводит к появлению
блоков HTML-кода, повторяющегося в каждой странице. В итоге, при хранении сайта
как коллекции HTML документов появляется большая избыточность информации.
Следующим недостатком первых реализаций сайтов является
ограниченность их взаимодействия с пользователями. Не могут быть поддержаны
такие возможности как персонификация предоставления и представления информации -
подбор материалов, новостей, на основе выбранных зарегистрированным посетителем
тем, общение между пользователями, в общем, всё что так или иначе связано с
необходимостью динамического формирования страниц.
Ещё одной трудностью является неудобная организация процесса
модификации имеющихся данных. Все изменения осуществляются одним
профессиональным лицом (или ограниченной группой лиц). В случае с часто
обновляющимся сайтом, таким как представительство СМИ, это неприемлемо - у
организации может быть штат авторов, но все новости проходят через одного
человека, что может привести к задержкам.
Для преодоления этих трудностей в последнее время создаётся
специальное программное обеспечение, способное автоматически генерировать HTML
страницы и предоставляющее удобные средства редактирования данных сайта. Такого
рода программные средства, называемые службами управления содержанием (CMS),
могут быть как универсальными, при наличии некоторых ограничений, заложенных в
их архитектуре, так и создаваться для нужд конкретного сайта. В последнем случае
они пригодны только для поддержки этого сайта.
Особенности
универсальных CMS.
В настоящий момент существует большое количество (уже порядка
двух сотен) таких систем, сильно отличающихся по своим характеристикам. Имеется
несколько систем, созданных крупными компаниями - Microsoft CMS, IBM WebSphere
Portal, BEA WebLogic Portal, Oracle Portal. В целом в данной области пока не
сложилось какого-нибудь общепризнанного стандарта, более того четко не
определены функциональные требования к таким программные средствам. Однако можно
выделить следующие требования, предъявляемые к таким продуктам:
- Удобный интерфейс редактирования данных
- Разделение данных и дизайна
- Управление доступом.
- Аудит.
- Способ хранения данных.
- Организация совместного доступа.
- Стандартные приложения.
- Открытость архитектуры / расширяемость.
Различия в
архитектуре.
Важным является анализ различий между этими системами,
поскольку он позволяют оценить несколько альтернативных подходов к решению части
задач.
Метод разделения
данных и оформления.
Как уже упоминалось, в настоящее время существуют два основных
подхода к генерации страниц: механизм шаблонов и XSLT преобразования.
Спецификация на XSLT появилась во второй половине 1999 года. Подход с
применением шаблонов исторически возник намного раньше, используется многими
системах.
К достоинствам метода шаблонов можно отнести простоту его
реализации. В результате возникло множество несовместимых между собой форматов.
Если шаблон должен являться чем-то большим, чем HTML страница с автоматически
заполняемыми полями, то это приводит к необходимости введения разнообразных
управляющих конструкций, обеспечения вставки кода на каком-то языке
программирования
Разделение дизайна и данных привело к разделению лиц,
работающих над сайтом, на редакторов информации и оформителей. Последние
вынуждены работать с языком шаблонов, предоставляемым системой. Применение новой
системы приводит к необходимости изучения нового (хотя нередко и похожего)
языка. Возникают проблемы при применении шаблонов, разработанных для предыдущих
систем. Использование XSLT устраняет часть этих недостатков, но вносит свои.
XML-язык XSLT (аббревиатура для XSL Transoformations, где XSL -
Extensible Style Language) позволяет задать правила, по которым из одних XML
документов формируются другие документы, чаще всего представляемые в форматах
XHTML и XML. Один и тот же шаблон может применяться для генерации различных
страниц. XSLT позволяет выполнять достаточно сложные манипуляции с исходными
данными, благодаря чему можно осуществлять практически любые осмысленные
преобразования. Пожалуй, единственным недостатком является только более низкая
производительность, чем генерация страниц на основе шаблонов. Отчасти это
компенсируется тем, что современные браузеры способны осуществлять
XSLT-преобразования на стороне клиента. Во многих случаях удается обеспечить
вполне эффективную "потоковую" обработку данных, когда XML данные представляются
как поток SAX-событий.
Права доступа и
организация процесса редактирования.
Для разграничения прав доступа и назначения ролевого участия
пользователей в управлении данными применяются различные технологии, часть
которых описана в этом разделе.
Одна их простых и наиболее широко распространенных - технология
на основе так называемых списков управления доступом (Access Control List, ACL).
В этом случае с каждым объектом ассоциируется таблица прав, определяющая, какие
операции с конкретным объектом может производить пользователь или группа
пользователей. Такой подход достаточно эффективен, если объекты образуют
иерархию - в этом случае права могут наследоваться, нет необходимости определять
их для каждого объекта. Однако это не позволяет поддержать практику, принятую,
например, при публикации печатных изданий - когда желательно назначать
пользователям роли, например, автор, редактор, а не определять их отношение
каждому ресурсу. Автор может только создавать материалы, редактор - проверять
созданный автором материал, выставить его в публичный доступ.
Наиболее полно такие возможности описывается концепцией
"потоков работ" (workflow). В рамках этой концепции можно накладывать
дополнительные ограничения и условия, в частности, временные рамки, можно более
точно описывать сложные сценарии подготовки информации. Существуют стандарты для
описания таких процессов, среди которых следует отметить XPDL (- XML Process
Definition Language [17,18].
Центральным понятием концепции "потоков работ" является
процесс, состоящий из множества "видов деятельности" (activity), связанных
"переходами" (transitions) от одного вида деятельности к другому. С каждым видом
деятельности связываются участники деятельности (персоны или приложения),
критерии, определяющие обстоятельства её начала и завершения. Каждому переходу
сопоставляются условия, при наступлении которых может быть осуществлен переход
от одного вида деятельности к другому. Если процессу сопоставить ориентированный
граф, то виды деятельности будут соответствовать его вершинам, а переходы -
дугам. Вид деятельности может иметь несколько входящих и исходящих переходов,
часть их которых может срабатывать одновременно, т.е. возможно распараллеливание
и слияние процессов. Переходы могут составлять циклы, которые соответствуют
повторяющимся видам деятельности.
Служба управления
слабоструктурированной информацией.
Требования к реализации.
От службы управления слабоструктурированными материалами в
основном требуется предоставить визуальные интерфейсы управления структурой и
данными разделов и подразделов содержания. Соответствующая схема данных описана
в следующем разделе. Для визуализации данных применяется технология XSLТ, что
нашло своё отражение в модели. Служба должна поддерживать управление доступом на
базе заданных прав доступа к объекту. Для организации наполнения и
редактирования материала должна применяться служба управления рабочими
процессами (workflow). Кроме этого, необходима поддержка обратной связи с
пользователями - поддержка комментирования, анкетирования, голосования, ведения
дискуссий и обсуждений.
Схема
данных.
Хранилище объектных данных предметной области является основным
сервисом нижнего уровня. При проектировании учитывались требования поддержки
произвольной иерархической структуры разделов и материалов, многоязычности
информации. Основные сущности схемы данных и их взаимоотношения приведены на
схеме.
Раздел - основной структурный элемент каталога
слабоструктурированных материалами. У каждого раздела может быть несколько
подразделов. На самом верхнем уровне расположен "корневой" раздел. Раздел
непосредственно не содержит каких-либо данных. Всё множество разделов
соответствует иерархии материалов сайта.
Вариант. Понятие варианта возникает из-за необходимости
поддержки многоязычной информации. Вариант раздела представляет информацию,
соответствующую одному из допустимых языков.
Дополнение представляет собой дополнительные данные,
ассоциированные с вариантом раздела. Различается три типа дополнений -
произвольные данные, хранящиеся в виде файлов на сервере, URL-ссылки и
XSP-запрос на включение структурированных данных ("динамических").
Поле непосредственно хранит данные раздела. Существуют два
типа полей - один из них предназначен для хранения произвольной строчки без
элементов форматирования, второй - фрагмент в формате HTML или XHTML.
В процессе разработки рассматривалось два метода хранения
данных - в СУБД, основываясь на стандартном для портала ИСИР способе отображения
объектов в базу, и в файловой системе в виде набора XML файлов. В результате
анализа было принять решение поддержать оба метода с возможностью выбора между
ними для конкретной установки системы. Метод хранения был инкапсулирован в API,
предоставляемом сервисом модели. В дальнейшем это позволяет, при необходимости,
добавлять другие варианты хранения без необходимости изменять существующий
код.
Поддержка
многоязыковых данных.
Потенциально модель поддерживает произвольное количество языков
для каждого из разделов, причём эти множества могут меняться произвольным
образом при переходах от раздела к разделу. На практике устанавливаются
некоторые ограничения с тем, чтобы для каждого из языков иерархия допустимых
разделов была связной и представляла собой дерево.
Выделяются два множества языков: языки данных и языки
интерфейса. Первое множество определяет, на каких языках может быть представлена
информация разделов, - определяет допустимые варианты разделов. Второе множество
содержит допустимые языки интерфейса пользователя. Язык интерфейса указывает,
какой вариант раздела, какое оформление должны использоваться при
соответствующей этому языку визуализации. Второе множество является
подмножеством первого.
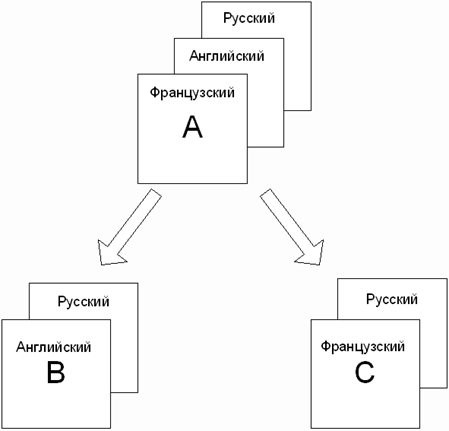 Пример иерархии изображен на рисунке, где показаны
разрешенные для визуализации варианты разделов. Набор имеющихся вариантов
разделов может быть любым, например, раздел B может иметь и вариант на
французском языке. Соответственно "карта сайта" будет различной для разных
языков интерфейса. В этом примере в карте сайта на русском языке будут
присутствовать все три раздела и по два раздела на английском и французском
языках.
Пример иерархии изображен на рисунке, где показаны
разрешенные для визуализации варианты разделов. Набор имеющихся вариантов
разделов может быть любым, например, раздел B может иметь и вариант на
французском языке. Соответственно "карта сайта" будет различной для разных
языков интерфейса. В этом примере в карте сайта на русском языке будут
присутствовать все три раздела и по два раздела на английском и французском
языках.
Если раздел не обладает разрешенным для визуализации вариантом,
то при выводе информации раздела для такого языка в соответствии с некоторым
алгоритмом выбирается наиболее подходящий из имеющихся
вариантов.
Система прав
доступа.
Для версии службы, не интегрированной сервисом потоков работ,
требуется какой-либо способ для разграничения прав доступа. В нашем случае имеет
смысл использовать ACL, поскольку, как уже упоминалось, он достаточно эффективен
в том случае, когда данные образуют иерархию. Системой поддерживаются понятия
"пользователя", "анонимного пользователя" и "группы пользователей", им
сопоставляются права доступа. Каждый раздел либо наследует права родительского
раздела, либо имеет собственный набор прав. По умолчанию права доступа
наследуются от раздела к подразделам.
Определены три допустимые операции: "запись", "просмотр в
системе управления" и "просмотр на сайте". Пользователи, по отношению к
заданному разделу обладающие правами на запись, могут осуществлять с ней все
доступные операции, в том числе и удаление. При отсутствии права на "просмотр в
системе управления" раздел будет недоступен пользователю. Введение этой операции
вызвано желанием, разрешить просмотр раздела через интерфейс редактирования без
права его модификации. "Просмотр на сайте" контролирует доступ пользователей к
разделам сайта. Как правило, анонимному пользователю предоставляется такое право
по отношению к корневом разделу. В сайте могут существовать внутренние разделы,
на которые это право не распространяется. Эти разделы могут просматривать только
зарегистрированные, авторизованные пользователи.
Визуальное
представление данных.
Визуальное представление данных является одним из наиболее
важных сервисов верхнего уровня, основная задача которого - предоставить
произвольному пользователю доступ к материалам портала по протоколу
HTTP.
Выбор
технологии.
Рассматривалось несколько вариантов реализации механизмов
визуализации материалов в рамках используемых технологий. Решение должно было
обладать максимальной гибкостью, требовались поддержка:
- XSLT как способа разделения дизайна и данных,
- генерация страниц на основе запросов
- кэширование генерируемых страниц.
В основном выбор делался между уже используемыми в ИСИР
вариантами:
- Jakarta Jetspeed - решение, ориентированное на поддержку портлетов,
- Apache Cocoon - решение, целиком основанное на поддержке XML и XSLT
технологий, наилучшие из подобного рода.
Оба варианта удовлетворяли предъявленным требованиям, но выбор
пал на Apache Cocoon. Это было обусловлено тем, что Apache Cocoon приспособлен
под такие задачи, как обработка и публикация XML данных, предоставляет
возможность более простой и изящной реализации. Тогда как JetSpeed является
более низкоуровневым проектом и в основном предназначен для разработки сайтов,
использующих технологию портлетов. На портлеты ограничений практически не
накладывается, соответственно нет собственных высокоуровневых средств,
организующих работу с XML данными, но в принципе при соответствующих доработках
допустимо использование Apache Cocoon в качестве такого
средства.
Атрибутно-полнотекстовый поиск.
Для посетителей сайта поиск является наиболее удобным средством
обнаружения необходимой информации. Несмотря на эффективность современных
поисковых машин, у них есть несколько существенных ограничений. Они индексируют
только открытую для внешнего мира часть сайта. Часто плохо индексируют
динамические страницы. Не всегда возможно организовать поиск только по
пространству сайта. Если даже это удалось осуществить, то актуальность индекса
сайта, как правило, запаздывает на несколько дней. Предоставляется только
полнотекстовый поиск.
Для полнотекстового индексирования хорошо разработаны методы
формирования индексов (инвертированные списки), даже имеются бесплатные
реализации. Однако, они плохо подходят для индексирования структурированных
данных, например, XML-данных и данных БД. По мере роста динамичности сайтов,
увеличения доли структурированных данных возникает потребность в иных решения,
способных обеспечить индексирование локальных данных и полнотекстовых и
структурированных. Одно из решений - использовать с этой целью возможности
реляционных СУБД. Такой подход был использован в рассматриваемой
системе.
Основные
понятия.
Ресурс -
полнотекстовые или структурированные текстовые
данные, для которых строится поисковый индекс. Примеры ресурсов: тестовый или
HTML файл, XML или RDF документ, данные БД, извлекаемые некоторой фиксированной
совокупностью связанных запросов.
Атрибут - контекст вхождения слов в текст ресурса. Атрибуты
используются для уточнения условий поиска и ранжирования. Пример атрибута -
"заголовок документа", "имя персоны".
Терм - вхождение цепочки символов алфавита, ограниченной
разделителями, в текст ресурса.
Индекс - информация о ресурсе, обеспечивающая выполнение
поисковых запросов.
Группа индексов - набор индексов, объединённый по
определенному признаку. Наиболее важный из таких признаков - наличие/состав
атрибутов.
Схема базы
данных.
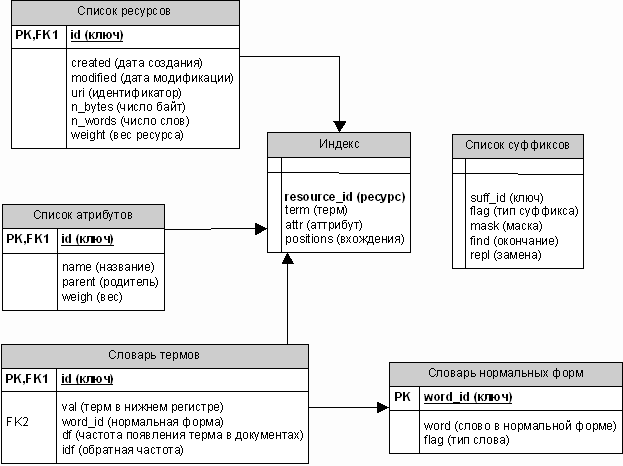
На данной ER-диаграмме представлены таблицы, используемые для
хранения индекса и сопутствующей информации. Сервис индексирования позволяет
создавать несколько групп индексов, при этом для каждой группы форми-руется свой
набор таблиц. Таблицы термов, нормальных форм и суффиксов являются общими для
всех групп индексов. Схема достаточно проста, за исключением частей,
поддерживающих процессы нормализации слов и ранжирования ресурсов.
В поле positions таблицы индекса заносятся информация о всех
вхождениях терма в текст конкретного ресурса. С этой целью формируется цепочка
позиций вхождений терма. Цепочка подвергается простому сжатию.
Индексирование.
Система умеет индексировать простые тексты, тексты с разметкой
(HTML, XML) и данные в RDF формате, в частности, данные из БД, выдаваемые
RDF-сериализатором. Процессы, происходящие при индексировании, изображены на
следующей диаграмме. Все процессы (разбор, выделение термов, создание индекса,
его временная запись в буфер, сохранение индекса) выполняются параллельно. При
этом одни поставляет данные для других. Зависимости по данным изображены на
диаграмме стрелками.
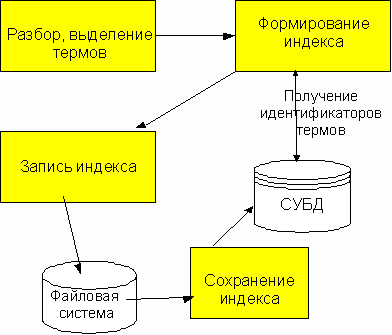
База данных задействована при формировании индекса и при его
сохранении. В первом случае она используется для идентификации термов по
словарю. Словарь пополняется новыми словами, когда обнаруживается, что какой-то
терм отсутствует в словаре. Поскольку процесс сохранения индекса в БД медленнее
процесса его формирования, процессы были разделены, и было обеспечено их
параллельное функционирование с синхронизацией через файловый
буфер.
Нормализация
термов.
Нормализация слов используется для поддержки поиска,
учитывающего словоформы слов. Нормализация может быть применена как в процессе
индексирования, так и только при обработке слов запроса - пополнение запроса
словоформами слов, заданных в запросе. Для этого в системе реализован механизм,
приводящий русские и английские слова языка к нормальной форме (именительный
падеж, единственное число). Механизм основан на алгоритме iSpell и его открытых
словарях.
Процесс нормализации выполняется независимо от процесса
индексирования. Это сделано для того, чтобы индексирование производилось с
максимально возможной скоростью, иначе нормализация замедляет процесс
индексирования примерно в два раза.
Распределенный
поиск.
Одним из наиболее важных требований, предъявляемых к решению,
является его масштабируемость. То есть, должна существовать возможность
построения сети серверов, в том числе географически удалённых. Основные задачи,
которые при этом появляются - это поддержка поиска по всем имеющимся в сети
данным, и реплицирование (создание и обновление копий) ресурсов. Если между
серверами существует хорошая связь, то выгодно осуществлять поиск путём
параллельного выполнения запроса на каждом из них и последующей агрегации
полученных данных. На основании некоторой метаинформации о сервере можно
предварительно принять решение о целесообразности направления к нему поискового
запроса. Возможен так же вариант полного реплицирования индексов, когда
формирование результата поискового запроса осуществляется без обращений к
удалённому серверу.
Особенности распределённого
поиска.
Централизованный поиск обладает следующими недостатками:
- Быстрое устаревание индексов
- На проверку того, что данные изменились, требуются ресурсы
- Трудность в доступе к базам данных
- Необходимость хранить большие индексы
- Трудности в масштабировании
- Зависимость от определённой архитектуры
Существуют три основных подхода к распределению поиска: "P2P" -
сеть состоит из индивидуальных компьютеров (не серверов), отсутствует формальный
процесс публикации ресурсов. Второй подход - метапоиск. Организуется единый
интерфейс для поиска, который опрашивает несколько поисковых машин. Последний
подход заключается в использовании стандартов распределённого поиска. При этом
определяется транспортный протокол, формат запросов, метод определения
релевантности. Однако стандарты могут и ограничивать добавление какой-либо своей
функциональности.
В случае с ИСИР используется смесь второго и третьего подхода
(ближе к третьему). У каждого сервера есть своя поисковая машина, понимающая
запросы, поступающие по протоколу SDLIP (Simple Digital Interoperability
Protocol). В силу однородности машин, это позволяет избежать всех недостатков
второго метода.
SDLIP.
Поддержка протокола SDLIP позволяет обеспечить распределенный
поиск по нескольким серверам. Она ещё хороша и тем, что с помощью SDLIP удобно
осуществлять и внутренний поиск. Это позволяет использовать единственный
программный интерфейс к системе поиска. Протокол SDLIP отличают такие важные
моменты, как:
- Простота реализации серверной и клиентской части.
- Поддержка различных транспортных протоколов, в частности, CORBA и HTTP.
- Возможность поддержки сессий на сервере.
- Масштабируемость.
- Поддержка кластеризации.
- Кэширование результатов поиска.
Операции SDLIP распределены по трём интерфейсам. Это сделано по
нескольким причинам: чёткое разделение ролей операций, возможность дальнейших
расширений, и возможность не поддерживать ненужные для определённого сервера
интерфейсы. Определены интерфейсы поиска, доступа к результатам, доступа к
метаданным.
Для объединения результатов поиска, полученных с нескольких
серверов, прежде всего, необходимо отбрасывать копии материалов (полученные
путём репликации данных). Что делается на основе их глобальных идентификаторов.
Есть несколько методов их получения, например, в случае с обычными материалами
сайта идентификаторы генерируются автоматически. Это не гарантирует их
уникальность, хотя вероятность их совпадения очень мала. Другим вариантом
является использование специального сервера, который хранит и генерирует
глобально уникальные идентификаторы, например, разработанный CRNI - "Handle
System". Помимо гарантирования уникальности, такой метод позволяет хранить (и
обновлять) дополнительную информацию о ресурсе.
Кроме удаления повторных результатов, необходимо обеспечить
совместное ранжирование результатов. Для этого используется единая методика для
вычисления ранга ресурсов.
Обмен
данными.
Совместный распределённый поиск эффективен при хорошей связи
между серверами, иначе он будет выполняться недопустимо медленно. Для ускорения
процесса в случае однородной системы используется обмен индексами. В более общей
постановке, есть необходимость обмена часто используемыми данными - индексами,
ресурсами. В качестве формата обмена естественно использовать RDF/XML. Для
протокола подобного обмена есть стандартные рекомендации - в первую это Common
Indexing Protocol (CIP). Изначально CIP был создан для передачи индексной
информации между серверами для поддержки распределения запросов, то есть
процесса репликации и перенаправления запросов к серверу, хранящему результаты,
в распределённой базе данных. Однако заложенные в нём идеи оказались полезны и
для обмена произвольными данными.
CIP определяет такие элементы, как:
Отношения между парой серверов в сети. Передача индекса между ними может
быть организована путём запроса/ответа (poll) или просто передачей индекса без
запроса получающей стороны (push).
Агрегирование индексов.
Транспортный протокол.
Представление передаваемых объектов в рамках стандарта MIME.
Протокол CIP описывает два достаточно общих метода
взаимодействия серверов. Первый метод - "push" - является достаточно простым.
Согласно ему, сервер, содержащий данные, просто время от времени передаёт их
другому серверу. Второй метод - "poll" - предполагает более сложное
взаимодействие серверов с возможностью использования уведомлений.
Для каждого из упомянутых выше сервисов, связанных с
распределением данных, рекомендован свой транспортный протокол. Для SDLIP - это
DASL или CORBA, протокол для CIP основан на telnet. В случае с ИСИР мы решили
для всех сервисов использовать один транспортный механизм - протокол SOAP. Это
имеет несколько преимуществ, прежде всего упрощение сетевых настроек и повышение
однородности системы. SDLIP достаточно просто переносится на SOAP, при этом
клиенты должны будут получить лишь новый транспортный модуль. Такой транспортный
модуль для SDLIP имеет и самостоятельную ценность. Что касается CIP, то, к
сожалению, это приводит к несовместимости нашей реализации с уже
существующими.
Литература
- Агошков С. В., Бездушный А. Н., Галочкин М. П., Кулагин М. В.,
Меденников А. М., Серебряков В. А., Интегрированная Система Информационных
Ресурсов (ИСИР) РАН - подход к созданию интегрированных цифровых библиотек //
Международная научная конференция "Электронные библиотеки: перспективные
методы и технологии, электронные коллекции", Санкт-Петербург.
- Бездушный А.Н., Жижченко А.Б., Кулагин М.В., Серебряков В.А.,
Интегрированная система информационных ресурсов РАН и технология разработки
цифровых библиотек. // Программирование V 26, N 4, 2000, pp. 177-185.
- Бездушный А.А., Бездушный А.Н., Жижченко А.Б., Кулагин М.В., Серебряков В.
А., RDF схема метаданных ИСИР. Роль технологий Semantic Web в архитектуре
ИСИР. // 2003, статья в данном сборнике
- Бездушный А.А., Нестеренко А.К., Сысоев Т.М., Бездушный А.Н., Java и XML
технологии новой версии системы ИСИР. // 2003, статья в данном сборнике
- Нестеренко А.К, Бездушный А.А., Сысоев Т.М., Бездушный А.Н., Возможности
службы управления потоками работ по манипулированию ресурсами репозитория
ИСИР. // 2003, статья в данном сборнике
- Стратегия выбора системы управления сайтом: сравнение систем по формальным
параметрам. //
http://business-site.ru/project/wsms/result.htm.
1999 Erich Gamma, Richard Helm, Ralph Johnson, John M. Vlissides. Design
Patterns: Elements of Reusable Object-Oriented Software.
Hiroshi Maruyama, Kent Tamura, Naohiko Uramoto. XML and Java: Developing
Web Applications.
R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, T.
Berners-Lee. Hypertext Transfer Protocol-HTTP/1.1.
Y. Goland, E. Whitehead, A. Faizi, S. Carter, D. Jensen. HTTP Extensions
for Distributed Authoring-WEBDAV.
J. Allen, M. Mealling. The Architecture of the Common Indexing Protocol
(CIP).
J. Allen, M. Mealling. MIME Object Definitions for the Common Indexing
Protocol (CIP).
J. Allen, P. Leach, R. Hedberg. CIP Transport Protocols.
Don Box, David Ehnebuske, Gopal Kakivaya, Andrew Layman, Noah Mendelsohn,
Henrik Frystyk Nielsen, Satish Thatte, Dave Winer. Simple Object Access
Protocol (SOAP) 1.1.
Simple Digital Library Interoperability Protocol
(www-diglib.stanford.edu/~testbed/ doc2/SDLIP).
Sergey Melnik, Sriram Raghavan, Beverly Yang, Hector Garcia-Molina.
Building a Distributed Full-Text Index for the Web.
Workflow Management Coalition standards // http://www.wfmc.org/standards/standards.htm
Workflow Process Definition Interface-XML Process Definition Language //
http://www.wfmc.org/standards/TC-1025_10_xpdl_102502.pdf
Материалы web конференций (groups.google.com).